Database Reference
In-Depth Information
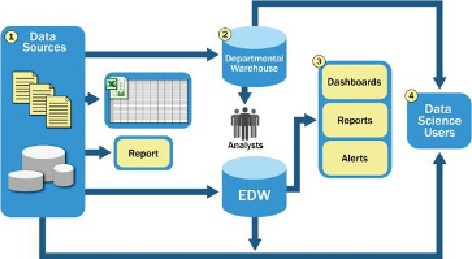
operational processes getting critical data feeds from the data warehouses
and repositories.
4. At the end of this workflow, analysts get data provisioned for their
downstream analytics. Because users generally are not allowed to run
custom or intensive analytics on production databases, analysts create
data extracts from the EDW to analyze data offline in R or other local
analytical tools. Many times these tools are limited to in-memory analytics
on desktops analyzing samples of data, rather than the entire population
of a dataset. Because these analyses are based on data extracts, they reside
in a separate location, and the results of the analysis—and any insights on
the quality of the data or anomalies—rarely are fed back into the main data
repository.
Figure 1.9
Typical analytic architecture
Because new data sources slowly accumulate in the EDW due to the rigorous
validation and data structuring process, data is slow to move into the EDW, and
the data schema is slow to change. Departmental data warehouses may have been
originally designed for a specific purpose and set of business needs, but over time
evolved to house more and more data, some of which may be forced into existing
schemas to enable BI and the creation of OLAP cubes for analysis and reporting.
Although the EDW achieves the objective of reporting and sometimes the creation
of dashboards, EDWs generally limit the ability of analysts to iterate on the data in
a separate nonproduction environment where they can conduct in-depth analytics
or perform analysis on unstructured data.
The typical data architectures just described are designed for storing and
processing mission-critical data, supporting enterprise applications, and enabling
corporate reporting activities. Although reports and dashboards are still important