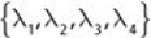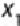Database Reference
In-Depth Information
Decision trees are computationally inexpensive, and it is easy to classify the data.
The outputs are easy to interpret as a fixed sequence of simple tests. Many decision
tree algorithms are able to show the importance of each input variable. Basic
measures, such as information gain, are provided by most statistical software
packages.
Decision trees are able to handle both numerical and categorical attributes and
are robust with redundant or correlated variables. Decision trees can handle
categorical attributes with many distinct values, such as country codes for
telephone numbers. Decision trees can also handle variables that have a nonlinear
effect on the outcome, so they work better than linear models (for example, linear
regression and logistic regression) for highly nonlinear problems. Decision trees
naturally handle variable interactions. Every node in the tree depends on the
preceding nodes in the tree.
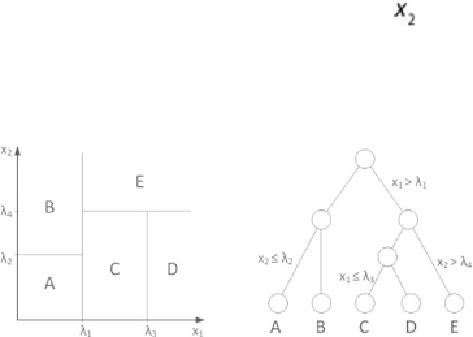
In a decision tree, the decision regions are rectangular surfaces.
Figure 7.8
shows
an example of five rectangular decision surfaces (A, B, C, D, and E) defined by
four values— —of two attributes ( and ). The corresponding
decision tree is on the right side of the figure. A decision surface corresponds to
a leaf node of the tree, and it can be reached by traversing from the root of the
tree following by a series of decisions according to the value of an attribute. The
decision surface can only be axis-aligned for the decision tree.
Figure 7.8
Decision surfaces can only be axis-aligned
The structure of a decision tree is sensitive to small variations in the training data.
Although the dataset is the same, constructing two decision trees based on two
different subsets may result in very different trees. If a tree is too deep, overfitting
may occur, because each split reduces the training data for subsequent splits.
Decision trees are not a good choice if the dataset contains many irrelevant
variables. This is different from the notion that they are robust with redundant
variables and correlated variables. If the dataset contains redundant variables, the