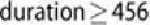Database Reference
In-Depth Information
repeated until the nodes are pure enough, or there is insufficient information
gain by splitting on more attributes. Alternatively, one can stop the growth of
the tree when all the nodes at a leaf node belong to a certain class (for example,
subscribed
= yes) or all the records have identical attribute values.
In the previous bank marketing example, to keep it simple, the dataset only
includes categorical variables. Assume the dataset now includes a continuous
variable called
duration
-representing the number of seconds the last phone
conversation with the bank lasted as part of the previous marketing campaign.
A continuous variable needs to be divided into a disjoint set of regions with the
highest information gain. A brute-force method is to consider every value of the
continuous variable in the training data as a candidate split position. This
brute-force method is computationally inefficient. To reduce the complexity, the
training records can be sorted based on the duration, and the candidate splits
can be identified by taking the midpoints between two adjacent sorted values. An
examples is if the duration consists of sorted values {140, 160, 180, 200} and the
candidate splits are 150, 170, and 190.
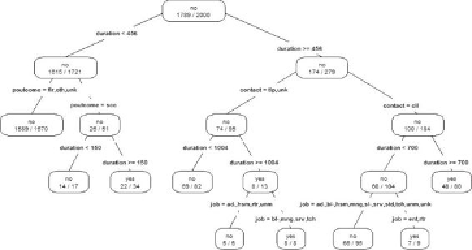
Figure 7.6
shows what the decision tree may look like when considering the
duration
attribute. The root splits into two partitions: those clients with
seconds, and those with seconds. Note that for
aesthetic purposes, labels for the
job
and
contact
attributes in the figure are
abbreviated.
Figure 7.6
Decision tree with attribute duration
With the decision tree in
Figure 7.6
,
it becomes trivial to predict if a new client
is going to subscribe to the term deposit. For example, given the record of a new
deposit. The traversed paths in the decision tree are as follows.