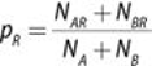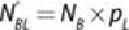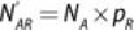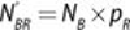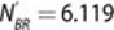Database Reference
In-Depth Information
The following measure computes the significance of a split. In other words, it
measures how much the split deviates from what would be expected in the random
data.
where
If K is small, the information gain from the split is not significant. If K is big, it
would suggest the information gain from the split is significant.
example.
,
,
,
,
,
.
Following are the proportions of data going to the left and right node.
and
.
The , , , and represent the number of each class going to the left or
right node if the data is random. Their values follow.
,
,
and
Therefore, , which suggests the split on
poutcome
is significant.
After each split, the algorithm looks at all the records at a leaf node, and the
information gain of each candidate attribute is calculated again over these records.
The next split is on the attribute with the highest information gain. A record
can only belong to one leaf node after all the splits, but depending on the
implementation, an attribute may appear in more than one split of the tree. This
process of partitioning the records and finding the most informative attribute is