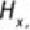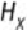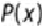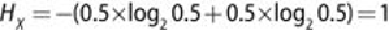Database Reference
In-Depth Information
The first step in constructing a decision tree is to choose the most informative
attribute. A common way to identify the most informative attribute is to use
entropy-based methods, which are used by decision tree learning algorithms such
as ID3 (or Iterative Dichotomiser 3) [7] and C4.5 [8]. The entropy methods select
the most informative attribute based on two basic measures:
•
Entropy,
which measures the
impurity
of an attribute
•
Information gain,
which measures the
purity
of an attribute
Given a class
and its label
, let
be the probability of .
the entropy
of , is defined as shown in
Equation 7.1
.
Equation 7.1
shows that entropy becomes 0 when all is 0 or 1. For a binary
classification (
true
or
false
), is zero if the probability of each label
is either zero or one. On the other hand, achieves the maximum entropy when
all the class labels are equally probable. For a binary classification, if the
probability of all class labels is 50/50. The maximum entropy increases as the
number of possible outcomes increases.
As an example of a binary random variable, consider tossing a coin with known,
not necessarily fair, probabilities of coming up heads or tails. The corresponding
entropy graph is shown in
Figure 7.5
. Let represent heads and
represent tails. The entropy of the unknown result of the next toss is maximized
when the coin is fair. That is, when heads and tails have equal probability
, entropy .
On the other hand, if the coin is not fair, the probabilities of heads and tails would
not be equal and there would be less uncertainty. As an extreme case, when the
probability of tossing a head is equal to 0 or 1, the entropy is minimized to 0.
Therefore, the entropy for a completely pure variable is 0 and is 1 for a set with
equal occurrences for both the classes (head and tail, or yes and no).