Database Reference
In-Depth Information
7.1.1 Overview of a Decision Tree
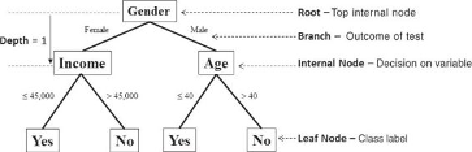
Figure 7.1
shows an example of using a decision tree to predict whether customers
will buy a product. The term
branch
refers to the outcome of a decision and is
visualized as a line connecting two nodes. If a decision is numerical, the “greater
than” branch is usually placed on the right, and the “less than” branch is placed on
the left. Depending on the nature of the variable, one of the branches may need to
include an “equal to” component.
Figure 7.1
Example of a decision tree
Internal nodes
are the decision or test points. Each internal node refers to
an input variable or an attribute. The top internal node is called the
root
. The
decision tree in
Figure 7.1
is a binary tree in that each internal node has no more
than two branches. The branching of a node is referred to as a
split
.
Sometimes decision trees may have more than two branches stemming from a
node. For example, if an input variable
Weather
is categorical and has three
choices—
Sunny
,
Rainy
, and
Snowy
—the corresponding node
Weather
in the
decision tree may have three branches labeled as
Sunny
,
Rainy
, and
Snowy
,
respectively.
The
depth
of a node is the minimum number of steps required to reach the node
one, and the four nodes on the bottom of the tree have a depth of two.
Leaf nodes
are at the end of the last branches on the tree. They represent class
labels—the outcome of all the prior decisions. The path from the root to a leaf node
contains a series of decisions made at various internal nodes.
branch contains all those records with the variable
Gender
equal to
Male
, and the
left branch contains all those records with the variable
Gender
equal to
Female
to
create the depth 1 internal nodes. Each internal node effectively acts as the root of
a subtree, and a best test for each node is determined independently of the other