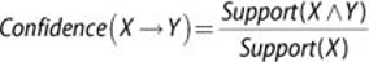Database Reference
In-Depth Information
5.3 Evaluation of Candidate Rules
Frequent itemsets from the previous section can form candidate rules such as X
implies Y (X
→
Y). This section discusses how measures such as confidence, lift, and
leverage can help evaluate the appropriateness of these candidate rules.
Confidence
[2] is defined as the measure of certainty or trustworthiness associated
with each discovered rule. Mathematically, confidence is the percent of transactions
that contain both X and Y out of all the transactions that contain X (see
Equation
For example, if
{bread,eggs,milk}
has a support of 0.15 and
{bread,eggs}
also has a support of 0.15, the confidence of rule
{bread,eggs}→{milk}
is 1,
which means 100% of the time a customer buys bread and eggs, milk is bought as
well. The rule is therefore correct for 100% of the transactions containing bread and
eggs.
A relationship may be thought of as interesting when the algorithm identifies the
relationship with a measure of confidence greater than or equal to a predefined
threshold. This predefined threshold is called the
minimum confidence
. A higher
confidence indicates that the rule (X
→
Y) is more interesting or more trustworthy,
based on the sample dataset.
So far, this chapter has talked about two common measures that the Apriori
algorithm uses: support and confidence. All the rules can be ranked based on these
two measures to filter out the uninteresting rules and retain the interesting ones.
Even though confidence can identify the interesting rules from all the candidate
rules, it comes with a problem. Given rules in the form of X
→
Y, confidence
considers only the antecedent (X) and the co-occurrence of X and Y; it does not take
the consequent of the rule (Y) into concern. Therefore, confidence cannot tell if a
rule contains true implication of the relationship or if the rule is purely coincidental.
X and Y can be statistically independent yet still receive a high confidence score.
Other measures such as lift [6] and leverage [7] are designed to address this issue.
Lift
measures how many times more often X and Y occur together than expected if
they are statistically independent of each other. Lift is a measure [6] of how X and Y
are really related rather than coincidentally happening together (see
Equation 5.2
)
.