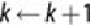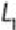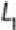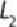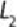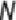Database Reference
In-Depth Information
10
11
return
The first step of the Apriori algorithm is to identify the frequent itemsets by
starting with each item in the transactions that meets the predefined minimum
support threshold . These itemsets are 1-itemsets denoted as , as each 1-itemset
contains only one item. Next, the algorithm grows the itemsets by joining onto
itself to form new, grown 2-itemsets denoted as and determines the support
of each 2-itemset in . Those itemsets that do not meet the minimum support
threshold are pruned away. The growing and pruning process is repeated until
no itemsets meet the minimum support threshold. Optionally, a threshold can
be set up to specify the maximum number of items the itemset can reach or the
maximum number of iterations of the algorithm. Once completed, output of the
Apriori algorithm is the collection of all the frequent
k
-itemsets.
Next, a collection of candidate rules is formed based on the frequent itemsets
uncovered in the iterative process described earlier. For example, a frequent
itemset
{milk,eggs}
may suggest candidate rules
{milk}→{eggs}
and
{eggs}→{milk}
.