Database Reference
In-Depth Information
media—hard drives—usually exhibit far superior sequential read/write
performance relative to random reads and writes.
Kafka uses essentially the same system as the write-ahead-log, maintaining
separate logs for each partition of each topic in the system. Of course,
Kafka is not a database. Rather than mutating a record in a database, Kafka
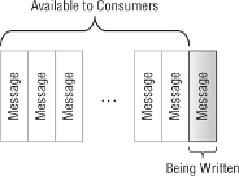
does not make a message available to consumers until after it has been
committed to the log, as shown in
Figure 4.1
.
In this way, no consumer can
consume a message that could potentially be lost in the event of a broker
failure.
In a post to LinkedIn's developer blog, Jay Kreps, one of Kafka's developers,
made an offhand comment that describes that Kafka implements “logs as
a service.” This could be taken quite literally, and Kafka could be used
to, essentially, implement a traditional relational database management
system (RDBMS) replication system. To do this, changes to the table in the
databasewouldbewrittentoKafkausingthenormalproducerprotocol.The
database itself would be a consumer of the Kafka data (in 0.8 this can be
accomplished using producer callbacks with the producer response set to
“all”replicas)andapplieschangesmadetothetablesbyreadingfromKafka.
To improve recovery times, it would occasionally snapshot its tables to disk
along with the last offset to be applied from each partition. It would appear
that Kafka's developers are also contemplating this style of application. The
log compaction proposal presented at
https://cwiki.apache.org/confluence/
display/KAFKA/Log+Compaction
indicates an environment where the
topic would be long-lived and allows consumers to recover the most recent
value for a given key. In a database application, this would cover recovery
and replication use cases. The key in a database application would represent
the primary keys of tables with the consumer application responsible for