Database Reference
In-Depth Information
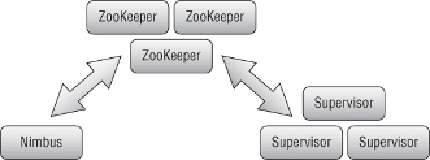
ZooKeeper
Adistributed Stormclusterrelies onZooKeeper forcoordinating thecluster.
Communication between nodes is peer-to-peer, so the load on the
ZooKeeper cluster is not very high as it is only used to manage metadata
for each of the nodes. If using a data motion system that also relies on
ZooKeeper, such as Kafka, it is fine to use that same cluster for hosting
Storm provided it has enough capacity.
ZooKeeper keeps track of all running topologies as well as the status of all
supervisors.
The Nimbus
The nimbus is the ringleader of the Storm circus. It is responsible for the
distribution of individual tasks for either spouts or bolts across the workers
in the cluster. It is also responsible for rebalancing a Storm cluster in the
event a supervisor has crashed.
At first glance, the nimbus would appear to be a single point of the failure,
like the
JobTracker
or
NameNode
in a traditional Hadoop cluster. For
Storm, this is not strictly the case. When the nimbus goes down, existing
topologies continue to function unimpeded. The Nimbus is not involved
in the moment-to-moment processing—just the distribution of processing
tasks to the supervisor nodes.
When the nimbus crashes, the cluster is no longer able to manage
topologies. This includes starting new topologies and rebalancing existing
topologies in the event of failure. It is recommended that nimbuses be
restarted as quickly as possible, but it will not immediately bring down a
cluster.