Database Reference
In-Depth Information
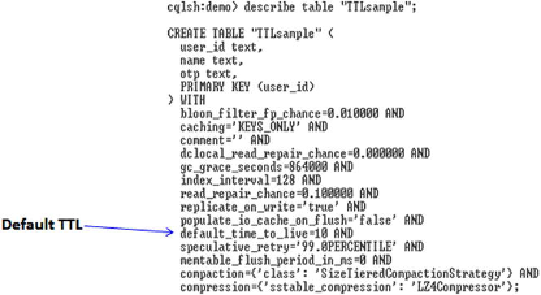
Figure 3-11
.
Output shows default TTL set to 10 seconds
Data Partitioning
Partitioning schema plays an important role in data distribution across nodes. Cas-
sandra offers three types of data partitioning strategies:
RandomPartitioner.
Selecting the Random partitioner would distrib-
ute data across the nodes using MD5 hashing algorithm. The random
partitioner would evenly distribute data in a cluster. Data distribution
would rely on assigned initial_token value or num_tokens for assign-
ing rows to each node. MD5 hashes are 16 bytes and are used to rep-
resent hexadecimal digits. Each node is assigned a data range that is
represented by the token value. On receiving read/write request, with
random partitioner selected as the partitioning strategy hash value for
each row key gets generated and assigned to the node responsible for
serving that read/write request. That's how data gets distributed with
random partitioning.
Murmur3Partitioner.
Default partitioner. Similar to RandomParti-
tioner but uses the Murmur Hash function for calculating the token
value. Murmur3 hash represents a 32- or 128-bit value, with Cas-
sandra it uses a 128-bit value for tokens. Another difference with
MD5 and murmur3 hashes is that the latter is noncryptographic hash-
ing whereas MD5 is cryptographic hashing function (e.g., one-way
hashing).