Database Reference
In-Depth Information
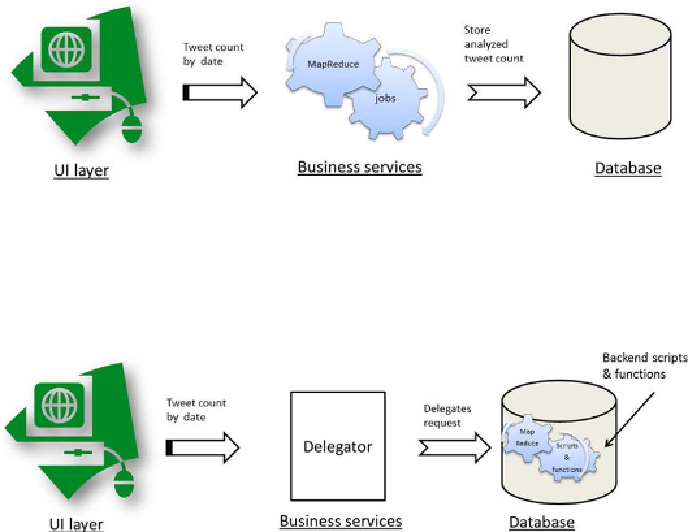
Figure 6-1
shows a MapReduce job execution of counting tweets by date on the
business layer (programmatically) and storing the output on a database. Here the
MapReduce algorithm implementation is on the application level. Such implementa-
tions can be Java or any other language.
Figure 6-1
.
Image depicting standard implementation of tweet analytics at business layer
Another implementation for the same use case can be that backend programmers or
data scientists prefer to write MapReduce scripts or functions on the database side, as
shown in
Figure 6-2
.
Figure 6-2
.
An image depicting implementation of tweet analytics at the database layer
Developing such MapReduce programs for almost everything is definitely not
maintainable and is time-consuming, as well. That's where an SQL-like language or
writing a simple script can be really helpful. Database administrators or scientists
might prefer a database-based approach (
Figure 6-2
) for quick implementation. With
this we can conclude that there is a space for requirement of such tools. For example,
these tools come in very handy to implement a scheduled job which requires extraction
over large data sets and stores output.
This comes with a question, are there any tools or open source libraries that are
available as a ready-to-use solution. Tools like Apache Hive, Apache Pig, and Sqoop