Information Technology Reference
In-Depth Information
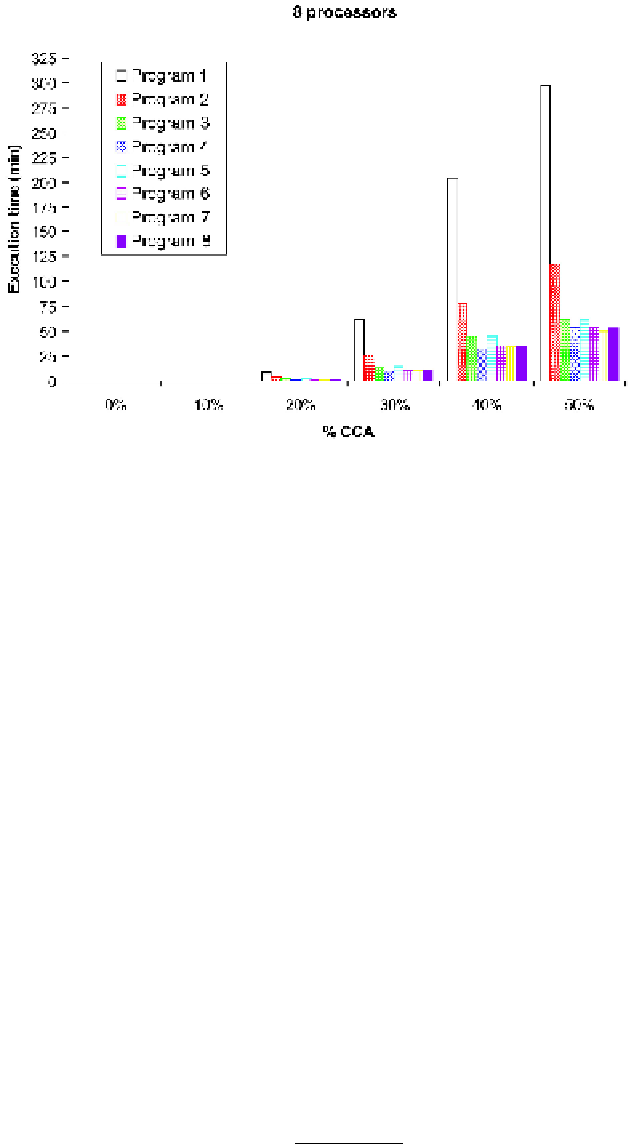
Fig. 5.
Execution times in minutes for each program using
8
processors
67
.
78%
, which implies an upwards trend with increasing the number of processors, as
expected. Moreover, we can observe that those programs including the parallelization
of task C, which implies an acceleration on the loop varying the CCA technology pen-
etration rate, are the fastest ones. Nevertheless, the results obtained from Program
2
show that the improvement achieved parallelizing only the vector-matrix multiplication
(task A) is already significant, reaching
60
.
4%
using
8
processors.
Analyzing the speedup for programs
7
and
8
it surprises that P
7
, with two parallelized
tasks, wins P
8
including one more task. But this is a common fact in parallel computing
due to load balancing and synchronization overhead [29]. This explains also that all
programs including parallelized task C have similar execution times, since this is the
heaviest computational task and outshines the improvement derived from the A and B
tasks parallelization.
Let us compare now the obtained results for the Program
7
, the one with the best
execution times, centering on the
50%
CCA penetration rate, since as we already men-
tioned, this is the heaviest option in terms of computational load. We find out an inverse
relationship between computation time and the number of processors in use, since when
we duplicate the number of processors the execution time of Program
7
is reduced al-
most to a half. Specifically, the speedup achieved passing from
2
to
4
processors is
1
.
82
,
and from
4
to
8
processors,
1
.
7
. However, this speedup is limited according to Amdahl's
law [30]. We have calculated for each program the theoretical speedup obtained from
this law, as depicted in Figure 6.
Amdahl's law states that if
α
is the proportion of a program that can be made parallel
then the maximum speedup,
SU
, that can be achieved by using
n
processors is:
1
(1
− α
)+
SU
=
.
(8)
α
n



Search WWH ::

Custom Search