Information Technology Reference
In-Depth Information
Fig. 2.
Probability tree diagram that defines the model.
S
i,j
represents the state with
i
collided
vehicles and
j
successfully stopped vehicles.
possible cases spring as well, that is either the following vehicle in the chain
C
2
may
collide or stop successfully. And so on until the last vehicle in the chain. At the last
level of the tree we have
N
+1
possible outcomes (final outcomes) which represent the
number of collided vehicles in the chain, that is, from
0
to
N
collisions (Figure 2).
The transition probability between the nodes of the tree is the probability of collision
of the corresponding vehicle in the chain
p
i
(or its complementary). These probabili-
ties are calculated recursively, regarding different kinematic parameters, as the average
velocity of the vehicles in the chain (used to compute the distance to stop), the average
inter-vehicle distance and the driver's reaction time, among others.
We start calculating the collision probability of the nearest to the incidence vehicle,
C
1
. The position of
C
i
when it starts to decelerate is normally distributed with mean
μ
i
=
−i ∗ d
and standard deviation
σ
=
d/
2
,where
d
is the average inter-vehicle
distance. Vehicle
C
1
will collide if and only if the distance to
C
0
is less than the distance
that it needs to stop,
D
s
, so its collision probability is given by:
−L−D
s
p
1
=1
−
f
(
x
;
μ
1
,σ
)
dx ,
(1)
−∞
where
L
is the average vehicle length and
f
(
x
;
μ, σ
)
is the probability density function
of the normal distribution with mean
μ
and standard deviation
σ
.
To compute the collision probability of the second vehicle we will use the average
position of the first vehicle when it has stopped (either by collision or successfully stop).
This average position is determined by:
−L
+
∞
X
1
=
x · f
(
x
;
μ
1
+
D
s
,σ
)
dx
+(
−L
)
·
f
(
x
;
μ
1
+
D
s
,σ
)
dx .
(2)
−∞
−L

























































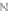






















Search WWH ::

Custom Search