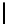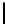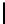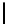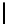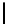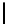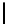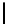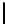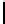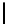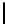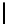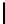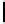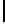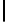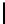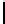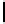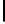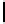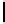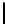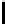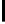Database Reference
In-Depth Information
Table 2.
DSM
Table 3.
MDSM
Columnk0
Key Va l ue
k1
Columnk2
Key Va l ue
k1
Jana
k2
Tobias
k3
Christian
k4
Tobias
k5
Tobias
k6
Jana
(a) Columns clustered on key
Columnk1
Key Va l ue
k1
Columnk1
Key Va l ue
k1
Columnk2
Key Va l ue
k1
Jana
k2
Tobias
k3
Christian
k4
Tobias
k5
Tobias
k6
Jana
(a) Columns clustered on key
Columnv0
Key Va l ue
k2
Columnv0
Key Va l ue
k2
Columnv2
Key Va l ue
k3
Christian
k1
Jana
k6
Jana
k2
Tobias
k4
Tobias
k5
Tobias
(b) Columns clustered on value
Columnv1
Key Va l ue
k3
20090327
137
731
20090327
137
20010925
k2
20071201
k3
173
k2
137
k2
20071201
k3
173
k6
20010925
k3
20010925
k5
317
k3
173
k3
20010925
k5
317
k2
20071201
k4
20090327
k4
371
k4
371
k4
20090327
k4
371
k1
20090327
k5
20090327
k6
713
k5
317
k5
20090327
k6
713
k4
20090327
k6
20010925
k1
731
k6
713
k6
20010925
k1
731
k5
20090327
(b)
Primary
key
columns
clustered
on value
DSM arise from high storage requirement of standard 2-copy DSM. The details
for the five variations of DSM are as follows:
Standard 2-copy DSM.
DSM is a transposed storage model [4], which pairs
each value of a column with the surrogate of its conceptual schema record as
key [10]. It suggests storing two copies of each column, one copy clustered on
values, whereas another copy is clustered on keys. DSM is depicted in Table 2.
We argue that for a self-tuning storage manager, 2-copy DSM is the most suitable
storage model. It is easy to implement and easy to use, moreover, it does not
require human intervention to identify which column to cluster or index, instead
it is done in a uniform way [20]. To justify our argument, we evaluated standard
2-copy DSM with four other variations and found it the most appropriate one.
The results are presented in Section 4.
Key-copy DSM (KDSM).
KDSM is the first variation of DSM that we pro-
pose to reduce the high storage requirement of the standard 2-copy DSM. KDSM
stores the data similar to DSM, i.e., for each column, data is stored in values,
whereas keys are unique numeric values that relate attributes of a row together.
All columns are clustered on the keys. However, unlike DSM, we store an extra
copy of only key columns (primary key or composite primary key) clustered on
values. This design alteration reduces the storage requirement of KDSM, but it
increases the access time for read operations that involve non-key columns in
search criteria. However, for read operations with the key column in the search
criteria it performs similar to DSM with less storage requirement as shown in
Section 4. We propose the use of KDSM for tables that only require querying
data using key columns.
Minimal DSM (MDSM).
MDSM stores the data similar to DSM except that
we do not store any extra copy for any columns thus reducing the high storage
requirement of DSM to a minimum. Instead, the design idea of MDSM is to store
primary key columns clustered on values, whereas non-primary key columns are
clustered on key as depicted in Table 3. MDSM performs similar to DSM and
KDSM for the read operations with search criteria on key column attributes,
but it performs worse for the read operations with non-key column attributes