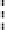Database Reference
In-Depth Information
C10D10K
Gazelle
400
250
BFS+P
DFS+P
PGA
BFS+P
DFS+P
PGA
350
200
300
250
150
200
100
150
100
50
50
0
0
0
2
4
6
8
0
0.01
0.02
0.03
0.04
0.05
θ
values (in %age)
θ
values (in %age)
Fig. 1.
Scalability of the three algorithms for decreasing values of
θ
,forsynthetic
dataset (
C10D10K
) (L) and for real dataset Gazelle (R)
C = 10,
θ
= 1%
D = 10K,
θ
= 25%
1600
BFS+P
DFS+P
PGA
1400
1000
1200
100
1000
800
10
600
400
1
BFS+P
DFS+P
PGA
200
0
0
0
40
80
120
160
0
20
40
60
80
No. of sources (in thousands)
No. of events per source
Fig. 2.
Scalability for increasing number of sources
D
, with average number of events
per source
C
= 10 and ES = 1% (L), and for increasing number of events per sources
C
with number of sources
D
=10
K
and ES = 25% (R)
4 Experimental Evaluation
In [12], the authors adapt GSP and SPADE/SPAM to yield a breadth-first (BFS)
and a depth-first (DFS) algorithm, respectively. In addition, they also propose
a probabilistic pruning technique to eliminate potential infrequent candidates
without support computation, achieving an overall speedup. We therefore, choose
two of the faster candidate generation variants from [12] i.e. BFS+P (breadth-
first search with pruning) and DFS+P (depth-first search with pruning), and
compare these with the Pattern-Growth Approach (PGA) proposed in this work.
Our implementations are in C# (Visual Studio .Net 2005), executed on a ma-
chine with a 3.2GHz Intel CPU and 3GB RAM running XP (SP3). We begin by
describing the datasets used for experiments. Then, we demonstrate the scalabil-
ity of the three algorithms. Our reported running times are averages from multiple
runs. In our experiments, we use both real (
gazelle
from Blue Martini [10]) and
synthetic (IBM Quest [2]) datasets. We transform these deterministic datasets to
probabilistic form in a way similar to [1,4,18,12]; we assign probabilities to each