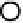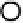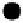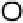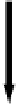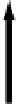Graphics Reference
In-Depth Information
b
i
m
ji
Figure A.2.
One iteration of belief prop-
agation. Node
i
collects incoming mes-
sages
m
ji
from its neighbors
{
)
∈
E
}
,
which are used to update its belief
b
i
about its label.
j
|
(
i
,
j
i
j
In loopy belief propagation, each node maintains an evolving
belief
about its
labeling — that is, a probability distribution function over the possible labels,
denoted at node
i
as
. The beliefs are iteratively updated by means
of
messages
passed along edges, denoted
{
b
i
(
k
)
,
k
=
1,
...
,
N
}
, that convey neighboring
nodes' current opinions about the belief at node
i
. The idea is sketched in Figure
A.2
.
The beliefs and messages are initialized as uniform distributions and iteratively
updated according to the following rules:
{
m
ji
,
(
i
,
j
)
∈
E
}
1
Z
B
φ
i
(
b
i
(
L
(
i
))
←
L
(
i
))
m
ji
(
L
(
i
))
(A.8)
j
|
(
i
,
j
)
∈
E
1
Z
M
max
φ
i
(
m
ij
(
L
(
j
))
←
L
(
i
))ψ
ij
(
L
(
i
)
,
L
(
j
))
m
hi
(
L
(
i
))
(A.9)
L
(
i
)
h
|
(
i
,
h
)
∈
E
,
h
=
j
This is called the
max-product algorithm
.
Z
B
in Equation (
A.8
) and
Z
M
in
Equation (
A.9
) are normalization constants so that the belief and message distri-
butions sum to one. The messages are updated a specified number of times or until
the beliefs stop changing significantly. The final label at node
i
is the one that max-
imizes
b
i
(
at convergence. The stereo algorithm given in Section
5.5.3
gives a
version of the max-product algorithm that operates on the data/smoothness terms
of Equation (
A.5
) (i.e., log likelihoods) instead of the potential functions.
If we replace Equation (
A.9
)by
L
(
i
))
N
1
Z
M
m
ij
(
L
(
j
))
←
1
φ
i
(
L
(
i
))ψ
ij
(
L
(
i
)
,
L
(
j
))
m
hi
(
L
(
i
))
(A.10)
i
=
h
|
(
i
,
h
)
∈
E
,
h
=
j
we obtain the
sum-product algorithm
, which results in estimates of the marginal
posterior at each node as opposed to the joint MAP estimate. Both algorithms are
widely used in computer vision problems (with the max-product algorithm slightly
more common).