Agriculture Reference
In-Depth Information
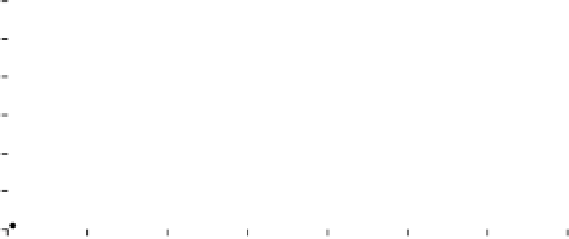
y = 0.73x
+
80.0
h
2
n
= 0.73
320
300
280
260
240
220
200
200
220
240
260 280
Mid-parent height (cm)
300
320
340
Figure 6.1
Scatter diagram of mid-parent phenotype height against average offspring progeny phenotype height from a
×
10
10 half diallel in
Brassica napus
.
The difference between the heterozygous (F
1
) and the
mid-parent value (m) is
d
.
To simply interpret a Hayman and Jinks' Analysis the
following assumptions are made:
From these, a number of parameters can be esti-
mated, including:
V
p
+
W
r
+
2
E
V
A
=
4
/
7
[
V
xr
]−
σ
4
V
r
−
V
D
=
V
A
•
Diploid segregation
The estimates of
V
A
and
V
D
indicate the amounts of
additive variance and dominance variance among the
crosses. This estimate of
V
D
assumes that F
1
progeny
are being evaluated (although other generations can be
accommodated). Obviously the frequency of heterozy-
gous alleles in a population will determine the degree of
dominance variation and this will vary with successive
rounds of selfing.
The most useful aspect of Hayman and Jinks' Anal-
ysis for plant breeders involves examination of variance
and covariance relationships and estimation of
V
A
or
V
D
. Therefore we will only cover the within array vari-
ances and between array covariances, how they can help
in determining the inheritance of the character of inter-
est, what the relationship of these two parameters means
in comparing different parental lines, and estimation
of
h
n
.
Based on the assumptions (listed above) of Hayman
and Jinks analyses we have
•
Homozygous parents
No difference between reciprocal crosses
•
No epistasis
•
No multiple alleles
•
Genes are distributed independently between the two
parents
•
But these assumptions are tested in the approach.
The parents and all possible F
1
progenies are eval-
uated for the trait of interest. All the offspring of one
parent used in crosses is called an
array
. That is, in all
crosses that the particular parent was used. Seven kinds
of variances and covariances are calculated including:
V
p
=
variance among the parent lines;
V
r
=
the variance among family
(
F
1
and reciprocal)
means within an array;
V
xr
=
variance among the means of the arrays;
V
r
=
1
4
(
mean value of all
V
r
over all arrays;
V
r
=
V
A
+
V
D
)
W
r
=
the covariance between families within
the
i
th array and their non-recurrent parent;
1
2
V
A
Consider now the relationship between
W
r
and
V
r
.
If we plot
W
r
against
V
r
, the regression line must have
W
r
=
W
r
=
mean value of
W
r
over all arrays;
2
E
σ
=
Error variance.