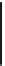Information Technology Reference
In-Depth Information
Fig. 5.5
Impact of
P
S
1.5
Social−Oblivious
Social−Aware
Social Optimal
1.4
1.3
1.2
1.1
1
0.9
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1
Probability of Social Edge
5.6.1
Erdos-Renyi Model Based Social Graph
We simulate the social graph based on the Erdos-Renyi (ER) graph model [
16
], where
a social edge exists between any two users with probability
P
S
. We assume that the
level of a social tie i
s 1
if it exists. We set the default values of parameters as follows:
N
=
10,
P
S
=
0
.
5,
C
=
3. For each set of parameter values, we average the results
over 1000 runs.
We illustrate the impact of
P
S
,
C
, and
N
on the normalized social welfare in
Figs.
5.5
,
5.6
, and
5.7
, respectively. We observe from these figures that socially-
aw
ar
e users significantly outperforms socially-oblivious users, especially when
P
S
or
C
is large, or
N
is small. This is due to that more users participate in pseudonym
change when they are socially-aware, which improves the social welfare. On the
other hand, the social welfare of socially-aware users is close to the optimal social
welfare. Figure
5.5
shows that the performance of socially-aware users improves
when
P
S
increases, with a performance gain up to 20 % over socially-oblivious
users and a performance gap about 10 % on average from the optimal social wel-
fare. This is due to that stronger social ties further encourage users to participate.
Figures
5.6
and
5.7
show that the performance gap of socially-oblivious users com-
pa
re
d to socially-aware users and the optimal social welfare, respectively, decreases
as
C
or
N
increases. This is because that, with a lower participation cost or higher
privacy gain of participation due to the increase of total user number, more users
would participate even when they are socially-oblivious. Therefore, the performance
gap reduces as it depends on the users that participate only when they are socially-
aware. We plot the number of iterations for running Algorithm 2 versus
N
in Fig.
5.8
.
We observe that the computational complexity increases almost quadratically as the
user number increases. This shows that our algorithm is scalable for a large number
of users.