Biomedical Engineering Reference
In-Depth Information
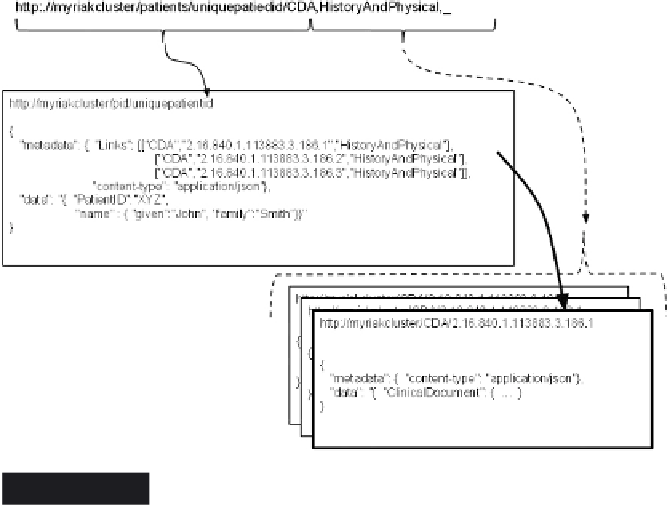
Figure 20.9
Riak RESTful API query
CDA documents corresponding to history and physicals are retrieved,
using an OID to identify each unique document held by the system. This
also highlights the simplicity and power of querying via a RESTful API
on fl exible data structures.
In this case, a MapReduce function would walk these links and inspect
each clinical document data segment. Algorithms would then inspect the
data for all medical codes, and map each medical code through the UMLS
vocabulary set. All documents with indications of acute heart disease and
the related data required would then be delivered to the reduction phase,
ready for processing via analytics engines.
20.7 Analytics
As discussed above, there are many architectural options for storing
CDA in fl exible schemas in large scalable distributed databases. A range
of transactional methodologies for working with these data are also
possible. The next challenge is to make sense of the wealth of content,
how do we visualize it, and how do we become confi dent of the contents
of potentially petabyte storage?




Search WWH ::

Custom Search