Biomedical Engineering Reference
In-Depth Information
future of clinical analytics therefore needs an architecture that admits
that the sources of data will never be perfectly normalized. Open source
communities have been the quickest to address these types of problems.
Architectural patterns created and contributed to the community by the
thought leaders in internet-scale computing can be leveraged to solve this
problem. In fact, solving these problems with these tools will one day
become the cheapest, simplest, and most highly scalable solution.
This chapter will introduce a prototypical architecture that can currently
satisfy various simple real-world scenarios but has not yet been fully
leveraged. There are several good reasons for this. Most of the trends and
capabilities introduced here have emerged in just the past few years. Yet
experience suggests that the total cost of development and ownership will
be orders of magnitude cheaper when these solutions hit their prime.
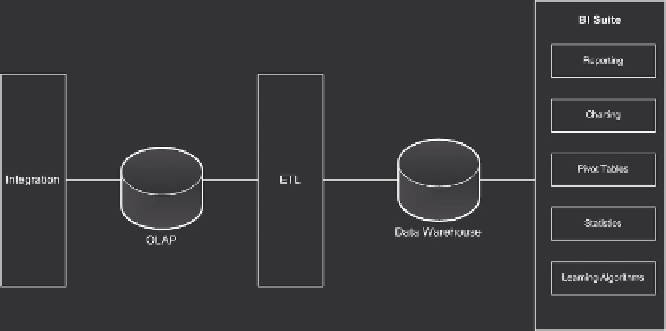
Figure 20.1 demonstrates a generic information technology view of the
components of the stack required to fulfi ll this domain. Most architects have
drawn this picture many times. To the left the integration layer brings in
detailed transactional information, not suitable for reporting. In the middle
we extract, transform, and load (ETL) these data into a data warehouse,
where data can be mined using the many reporting tools available.
Many architects have also come to understand that the traditional
model described in Figure 20.1 is very expensive to scale to extremely
large volumes. In response, this chapter will survey many open source
technologies that describe a potential solution addressing both clinical
requirements and extreme scales. Throughout the text, a simple use-case
of researching potential factors of acute heart disease is presented, to
provide a sense of how the technology would work in the real world. The
Figure 20.1
Architecture for analytical processing
























Search WWH ::

Custom Search