Biomedical Engineering Reference
In-Depth Information
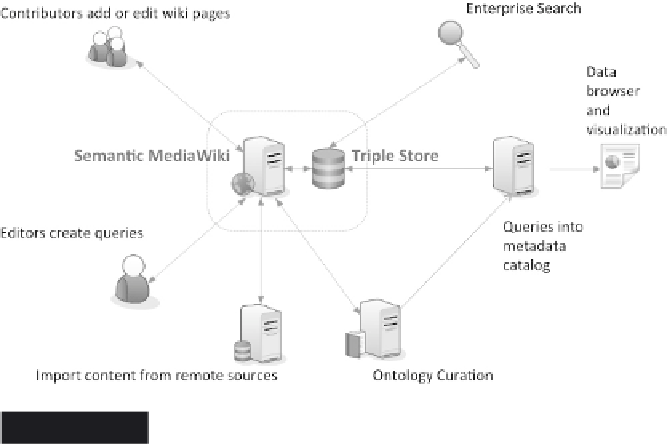
Semantic MediaWiki and Linked Data Triple Store
working in parallel
Figure 16.7
16.3.13 Incremental indexing of enterprise
search
As a fi rst application, we created an XML connector from KnowIt
to our enterprise search engine. SPARQL queries to the wiki can
now be used to control which content should be indexed. Integration
with existing search engines is important as it allows content of the
wiki to be seamlessly available to users unfamiliar with the wiki. For
instance, this allows scientists to search for data sources that
contain terms such as 'gene sequencing' and 'proteins' and see a
resulting list of all relevant data sources internal and external to the
enterprise.
Although this application is possible using the basic query mechanism
from Semantic MediaWiki, SPARQL queries make it possible to
formulate elaborate fi lters on pages to update, and index them based on
modifi cation date or other criteria. Eventually, this mechanism will allow
us to fi lter out pages that should not be indexed, and will provide the
search engine complete semantic annotations when RDF content is
available. This allows a reduction of the impact of crawling on the
server, better use of network bandwidth and better control of what to
index [19].



Search WWH ::

Custom Search