Databases Reference
In-Depth Information
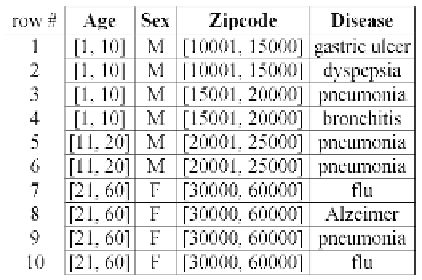
Table 2.
A 2-anonymous version of Table 1a
Sarah, the neighbor examines the generalized QI-values in Table 2. Obviously,
Tuple 1 cannot be owned by Sarah, since it
Age
-value [1, 10] does not cover 28.
By this reasoning, Tuples 7-10 (in the last QI-group) are the only candidates
for the tuple of Sarah. Unable to make additional inferences from here, the
adversary settles on a fuzzy fact: Sarah may have got
flu
,
pneumonia
,or
Alzeimer's
.
Unlike Table 1a which allows the adversary to exactly derive the private
value of Sarah, Table 2 offers stronger protection. Evidently, protection is
made possible by the fact that generalization prevents the unique association
of a tuple to its owner. Specifically, since Tuples 7-10 share the same QI
formats, with a random guess, an adversary has only a 1
/
4 chance of correctly
identifying Tuple 9 as the real tuple owned by Sarah.
Based on the above idea, Sweeney and Samarati [14] propose
k-anonymity
as an anonymization principle to measure the degree of generalization. For-
mally, a generalized table is
k-anonymous
if each QI-group contains at least
k
-tuples. Table 2 is 2-anonymous, since the smallest QI-group (involving the
first two rows) has a size 2. In general, a higher
k
provides stronger protection
because, in general,
k
-anonymity guarantees that an adversary has at most
1
/k
probability of finding out the actual tuple owned by the victim individ-
ual. As a tradeoff, however, increasing
k
also brings down the utility of the
generalized table, since more information must be lost in generalization. This
can be easily understood through an extreme example:
k
=
.Inthatcase,
all the tuples in the microdata
T
must be included in a single QI-group. As a
result, each generalized value must be a (very!) long interval encompassing all
the values in
T
on the corresponding QI-attribute. For instance, if
k
equals
10 and
T
is Table 1a, after generalization each
Age
-value becomes an interval
that covers the range [5
,
56]. Releasing such an excessively generalized table
is hardly more useful than publishing only the
Disease
-column of
T
.
A large bulk of research has been devoted to developing algorithms
[3, 6, 7, 8, 9, 13, 15, 17, 19] for computing a
k
-anonymous version of
T
,
|
T
|