Databases Reference
In-Depth Information
criteria (similar criteria are found in various frameworks, e.g., [16]). The fit
tuples set will then contain roughly
N
e
elements.
The “fitness” selection step provides several advantages. On the one hand
this ensures secrecy and resilience and, on the other hand, it effectively “mod-
ulates” the watermark encoding process to the actual attribute-primary key
association. Additionally, this is the place where the cryptographic safety
of the hash one-wayness is leveraged to defeat invertibility attacks (
A5
). If
K
A
Issue:
is the data watermarked ? if yes
then what is the watermark
string
?
0
a
3
1
a
7
wm[1]
[2]
[3]
[4]
…
[g(i)]
…
[m-1]
[m]
2
a
9
bias
true
[1]
…
bias
false
[1]
…
3
a
2
…
g(i)=msb(H(i,k
2
),log
2
(m))
i
a
f(i)
…
Solution:
slightly alter
A
,
modulating some of its
("fit") values according to
a one-way hash of
K
and
a
spread of the values of
the watermark
w
.
n-1
a
8
n
a
7
f(i)=msb(H(i
⊕
w[g(i)],k
1
),log
2
(n
A
))
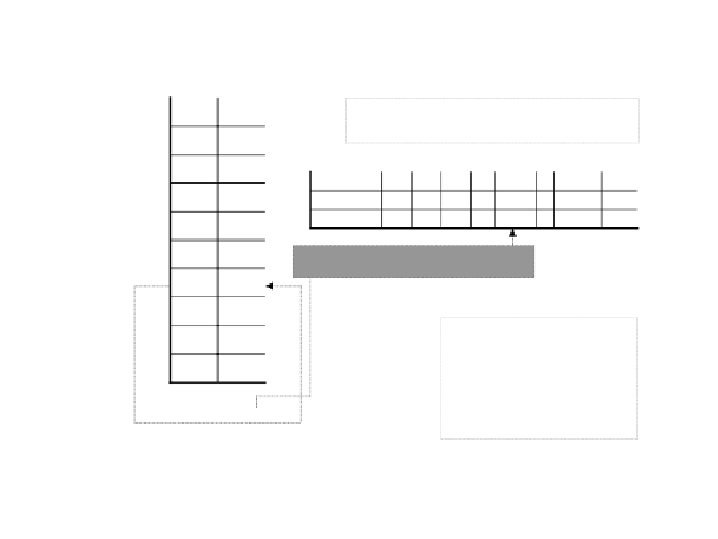
Fig. 12.
Overview of multi-bit watermark encoding.
N
e
the available embedding bandwidth
is greater than the watermark bit-size
|
, error correcting codes (ECC) are deployed that take as input a desired
watermark
wm
and produce as output a string of bits
wm data
of length
N
wm
|
e
containing a redundant encoding of the watermark, tolerating a certain
amount of bit-loss,
wm data
=
ECC.encode
(
wm,
e
).
Step Two. For each “fit” tuple
T
i
, we encode one bit by altering
T
i
(
A
)to
become
T
i
(
A
)=
a
t
where
t
=
set bit
(
msb
(
H
(
T
i
(
K
)
,k
1
)
,b
(
n
A
))
,
0
,wm data
[
msb
(
H
(
T
i
(
K
)
,k
2
)
,b
(
N
e
))])
and
k
2
is a secret key
k
2
=
k
1
. In other words, a secret value of
b
(
n
A
) bits
is generated - depending on the primary key and
k
1
- and then its least
significant bit is forced to a value according to a corresponding position in
wm data
(random, depending on the primary key and
k
2
). The new attribute