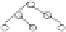Databases Reference
In-Depth Information
...
...
k
l
p
l
h
l
=
H
(h
r
1
|
...
|
h
rf
k
)
...
...
...
k
i
p
i
h
i
=
H
(r
i
)
...
embedded tree's root
k
rj
...
...
p
rj
h
rj
Fig. 5.
An EMB-tree node.
The Embedded Merkle B-tree
In this section we present another data structure, the Embedded Merkle B-
tree (EMB-tree), that provides a nice, adjustable trade-off between robust
initial construction and storage cost versus improved
construction and
verification cost. The main idea is to have different fanouts for storage and
authentication and yet combine them in the same data structure.
Every EMB-tree node consists of regular
B
+
-tree entries, augmented with
an embedded MB-tree. Let
f
e
be the fanout of the EMB-tree. Then each
node stores up to
f
e
triplets
k
i
|
VO
h
i
, and an embedded MB-tree with fanout
f
k
<f
e
. The leaf level of this embedded tree consists of the
f
e
entries of the
node. The hash value at the root level of this embedded tree is stored as an
h
i
value in the parent of the node, thus authenticating this node to its parent.
Essentially, we are collapsing an MB-tree with height
d
e
·
p
i
|
d
k
= log
f
k
N
D
into
a tree with height
d
e
that stores smaller MB-trees of height
d
k
within each
node. Here,
d
e
= log
f
e
N
D
is the height of the EMB-tree and
d
k
= log
f
k
f
e
is
the height of each small embedded MB-tree. An example EMB-tree node is
shown in Figure 5.
For ease of exposition, in the rest of this discussion it will be assumed that
f
e
is a power of
f
k
such that the embedded trees when bulk-loaded are always
full. The technical details if this is not the case can be worked out easily. The
exact relation between
f
e
and
f
k
will be discussed shortly. After choosing
f
k
and
f
e
, bulk-loading the EMB-tree is straightforward: Simply group the
N
D
tuples in groups of size
f
e
to form the leaves and build their embedded trees
on the fly. Continue iteratively in a bottom up fashion.
When querying the structure the server follows a path from the root to the
leaves of the external tree as in the normal
B
+
-tree. For every node visited, the
algorithm scans all
f
e
−
h
i
on the data level of the embedded
tree to find the key that needs to be followed to the next level. When the
right key is found the server also initiates a point query on the embedded tree
of the node using this key. The point query will return all the needed hash
values for computing the concatenated hash of the node, exactly like for the
MB-tree. Essentially, these hash values would be the equivalent of the
f
e
−
1 triplets
k
i
|
p
i
|
1
sibling hashes that would be returned per node if the embedded tree was not
used. However, since now the hashes are arranged hierarchically in an
f
k
-way