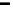Database Reference
In-Depth Information
TABLE 9.4
Contents of the H5Part file generated in
Table 9.3
GROUP ”/”
{
GROUP ”Step#0”
{
DATASET ”px”
{
DATATYPE H5T IEEE F64LE
DATASPACE SIMPLE
{
( 1000 ) / ( 1000 )
}
}
DATASET ”py”
{
DATATYPE H5T IEEE F64LE
DATASPACE SIMPLE
{
( 1000 ) / ( 1000 )
}
}
DATASET ”pz”
{
DATATYPE H5T IEEE F64LE
DATASPACE SIMPLE
{
( 1000 ) / ( 1000 )
}
}
DATASET ”x”
{
DATATYPE H5T IEEE F64LE
DATASPACE SIMPLE
{
( 1000 ) / ( 1000 )
}
}
DATASET ”y”
{
DATATYPE H5T IEEE F64LE
DATASPACE SIMPLE
{
( 1000 ) / ( 1000 )
}
}
DATASET ”z”
{
DATATYPE H5T IEEE F64LE
DATASPACE SIMPLE
{
( 1000 ) / ( 1000 )
}
}
GROUP ”Step#1”
{
...information for 6 datasets...
}
}
data analysis application to read from a directory full of files instead of just
one file. An arguably better approach is to provide the means for a parallel
application to write data into a single file from all processing elements (PEs),
which is known as
collective I/O
. Collective I/O performance is typically (but
not always) lower than that of writing one file per processor, but it makes
data management much simpler after the program has finished. No additional
recombinination steps are required to make the file accessible by visualization
tools or for restarting a simulation using a different number of processors.
Parallel HDF5 uses MPI-IO for its low-level implementation. The mechanics
of using MPI-IO are hidden from the user by the H5Part API (the code looks
nearly identical to reading/writing the data from a serial program). While