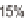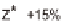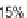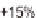Geoscience Reference
In-Depth Information
Fig. 12.7
Probability intervals
for classification
Probability
to be within
95% 80% 50%
resources are those for which the expected monthly produc-
tion is within ± 15 % of the true value 95 % of the time. Indi-
cated resources are those for which the condition is relaxed to
80 % of the time, while Inferred only requires that 50 % of the
time (or production months) the true value be within ± 15 %.
Uncertainty predictions can be from geostatistical or more
traditional methods. If geostatistical procedures are used to
construct probability distributions of uncertainty the param-
eters vary locally and within domains. There are a number of
techniques that can be used, but conditional simulation is the
best option, since the uncertainty of any parameter of interest
can be predicted at different scales by simply averaging up
the simulated values.
The uncertainty model can be checked by predicting the
uncertainty at locations where there is information from
drillholes or past production data. The probability intervals
are constructed, counting the number of times that the true
values fall within those intervals, thus determining if the pre-
dicted percentage is verified.
In any resource estimation work, the purpose of classify-
ing the estimated resources should be clearly stated, and also
a clear distinction between geologic confidence (i.e., resource
classification) and mining risk assessment should be made. It
is tempting to use resource categories as a means to obtain a
mine production risk assessment, although they are intended
for geologic confidence assessment in a very global sense.
There is no consistent scheme for resource classification
for all deposits, although certain common practices can be
identified.
Another alternative is to otain the average weighted dis-
tance of all samples used to estimate the block. This dis-
tance could be anisotropic, following the variogram model
ellipsoid and/or the shape of the search neighborhood. It may
appear as a reasonable option since
all
samples used in the
estimation are considered. This could potentially avoid arti-
facts related to assigning high confidence to a block estimat-
ed with one very close sample and many others much fur-
ther away. But there are drawbacks with this system, again
related to the lack of uncertainty measures and the simple
criteria used.
The actual classification of the resources should depend
on the distances chosen to characterize confidence, which in
turn should be based on geology, drilling density and vario-
gram ranges. Commonly, different estimation domains will
have different classification parameters applied to them.
Also, a minimum number of samples and drilling density
measures are sometimes used, as well as differences in the
geologic characteristics in different areas of the deposit.
12.3.2
Resource Classification Based on Kriging
Variances
The kriging variance is an index of data configuration. As
such, it can be used to rank the resource model blocks based
on how much information is used to estimate each block. It
can be standardized, for example, to a local mean, such that
the resulting relative kriging variance can be used across dif-
ferent grade mineralization zones.
The values for kriging variances that define resource cat-
egories are usually related to a pre-specified drill hole con-
figuration, as exemplified in Fig.
12.8
. This is an example
taken from a porphyry copper deposit in northern Chile. After
obtaining a variogram model for each of the three main cop-
per mineralization types present in the deposit, two standard
drill hole configurations were used as references to deter-
mine resource categories. The kriging variance values for the
5-composite configuration (Case B) defines the limit between
measured and indicated for each mineralization type, while
12.3.1
Resource Classification based on Drill
Hole Distances
Multiple variants of this concept have been used, but in its
most simple form the resource is classified based on the dis-
tance from the centroid of the estimated block to be to the
nearest sample used in the interpolation. Estimated blocks
that have close samples nearby will have a higher confidence
assigned to them. This is considered a very simplistic method.