Hardware Reference
In-Depth Information
node
node
node
node
R
R
R
R
MCU
MCU
node
node
node
node
R
R
R
R
node
node
node
node
R
R
R
R
MCU
MCU
node
node
node
node
R
R
R
R
R
router
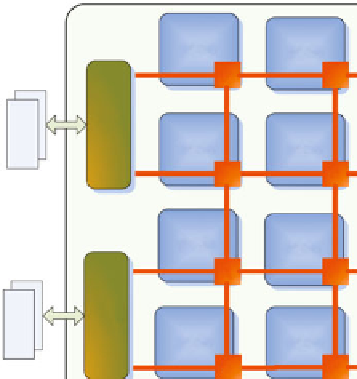
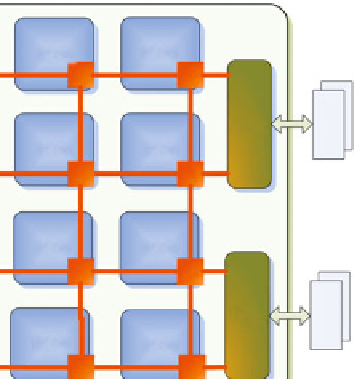
Fig. 8.6
The ICT Many-Core architecture (
transformer
)
which implements the interconnection network. Specifically, each node implements
a two-issue out-of-order pipelined processor architecture with an independent pro-
gram counter and a two-level cache hierarchy. The memory sub-system is
distributed
(thus not shared among cores) to simplify the architecture of the system.
8.3.2
Node Architecture and Instruction Set
For each node there is a separate level 1 instruction/data cache and a unified level 2
cache in each node. As there is need for 64-bit computing in multimedia applications,
64-bit MIPS-III ISA is chosen for the node. Some MAC (Multiply-Accumulate)
instructions which need three source operands are also supported by node.
Each node implements a two-issue out-of-order pipelined processor architecture,
as shown in Fig.
8.7
. The pipeline is divided into 6 stages: fetch, decode, map,
issue, execute and write back. For memory operations, there is one more stage
data
cache
between
execute
and
write back
. In order to achieve reasonable performance
and implement a low complexity node, a
scoreboard
-based out-of-order pipeline
based is used. The scoreboard unit in each node is responsible for accepting decoded
instructions from the
map
stage, and issuing them to the functional units (address
generators, ALUs and FPUs) satisfying dependencies among the instructions. To
achieve this goal the main element of the scoreboard is the instruction queue which
holds decoded instructions and issues them once the resources they require are free
and their dependencies have been cleared.

Search WWH ::

Custom Search