Information Technology Reference
In-Depth Information
Figure 5.85:
Face animation decoder used facial definition parameters (FDP) to create a neutral face. Facial
animation parameters (FAPs) are specialized vectors which move the face vertices to reproduce expressions.
In face coding, the human face is constructed in the decoder as a three- dimensional mesh onto which the
properties of the face to be coded are mapped. Figure 5.85 shows a facial animation decoder. As all faces have the
same basic layout, the decoder contains a generic face which can be rendered immediately. Alternatively the
generic face can be modified by
facial definition parameters
(FDP) into a particular face. The data needed to do
this can be moderate.
The FDP decoder creates what is known as a neutral face; one which carries no expression. This face is then
animated to give it dynamically changing expressions by moving certain vertices and re-rendering. It is not
necessary to transmit data for each vertex. Instead face-specific vectors known as
face animation parameters
(FAPs) are transmitted. As certain combinations of vectors are common in expressions such as a smile, these can
be coded as
visemes
which are used either alone or as predictions for more accurate FAPs. The resulting vectors
control algorithms which are used to move the vertices to the required places. The data rate needed to do this is
minute; 2-3 kilobits per second is adequate.
In body animation, the three-dimensional mesh created in the decoder is a neutral human body; i.e. one with a
standardized posture. All the degrees of freedom of the body can be replicated by transmitting codes
corresponding to the motion of each joint.
In both cases if the source material is video from a camera, the encoder will need sophisticated algorithms which
recognize the human features and output changing animation parameters as expression and posture change.
5.30 Scaleability
MPEG-4 offers extensive support for scaleability. Given the wide range of objects which MPEG-4 can encode,
offering scaleability for virtually all of them must result in considerable complexity. In general, scaleability requires
the information transmitted to be decomposed into a base layer along with one or more enhancement layers. The
base layer alone can be decoded to obtain a picture of a certain quality. The quality can be improved in some way
by adding enhancement information.
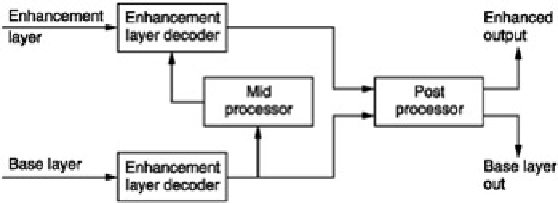
Figure 5.86 shows a generic scaleable decoder. There is a decoder for the base layer information and a decoder
for the enhancement layer. For efficient compression, the enhancement layer decoder will generally require a
significant number of parameters from the base layer to assist with predictively coded data. These are provided by
the
mid-processor
. Once the base and enhancement decoding is complete, the two layers are combined in a post-
processor.
Figure 5.86:
A generic scaleable decoder contains decoding for base and enhancement layers as well as a mid-
processor which adapts the base layer data to the needs of the enhancement process.