Information Technology Reference
In-Depth Information
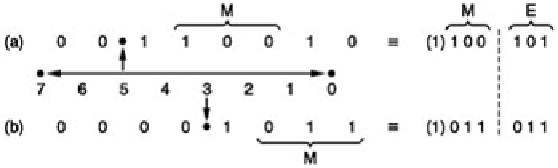
Figure 4.23:
In this example of floating-point notation, the radix point can have eight positions determined by the
exponent E. The point is placed to the left of the first '1', and the next four bits to the right form the mantissa M. As
the MSB of the mantissa is always 1, it need not always be stored.
Clearly in floating-point the signal-to-noise ratio is defined by the number of bits in the mantissa, and as shown in
Figure 4.24
, this will vary as a sawtooth function of signal level, as the best value, obtained when the mantissa is
near overflow, is replaced by the worst value when the mantissa overflows and the exponent is incremented.
Floating-point notation is used within DSP chips as it eases the computational problems involved in handling long
wordlengths. For example, when multiplying floating-point numbers, only the mantissae need to be multiplied. The
exponents are simply added.
Figure 4.24:
In this example of an eight-bit 8 = 48 dB with
×
mantissa, three-bit exponent system, the maximum
SNR is 6 dB maximum input of 0 dB. As input level falls by 6 dB, the convertor noise remains the same, so SNR
falls to 42 dB. Further reduction in signal level causes the convertor to shift range (point A in the diagram) by
increasing the input analog gain by 6 dB. The SNR is restored, and the exponent changes from 7 to 6 in order to
cause the same gain change at the receiver. The noise modulation would be audible in this simple system. A
longer mantissa word is needed in practice.
A floating-point system requires one exponent to be carried with each mantissa and this is wasteful because in real
audio material the level does not change so rapidly and there is redundancy in the exponents. A better alternative
is floating-point block coding, also known as near-instantaneous companding, where the magnitude of the largest
sample in a block is used to determine the value of an exponent which is valid for the whole block. Sending one
exponent per block requires a lower data rate than in true floating-point.
[
14
]
In block coding the requantizing in the coder raises the quantizing error, but it does so over the entire duration of
the block.
Figure 4.25
shows that if a transient occurs towards the end of a block, the decoder will reproduce the
waveform correctly, but the quantizing noise will start at the beginning of the block and may result in a burst of
distortion products (also called pre-noise or pre-echo) which is audible before the transient. Temporal masking may
be used to make this inaudible. With a 1 ms block, the artifacts are too brief to be heard.
Figure 4.25:
If a transient occurs towards the end of a transform block, the quantizing noise will still be present at
the beginning of the block and may result in a pre-echo where the noise is audible before the transient.
Another solution is to use a variable time window according to the transient content of the audio waveform. When
musical transients occur, short blocks are necessary and the coding gain will be low.
[
15
]
At other times the blocks
become longer allowing a greater coding gain.