Biomedical Engineering Reference
In-Depth Information
that all cluster units are not equally utilized during the training process. Often during
training only a few cluster units will be updated and this leads to unwanted distortions
and misclassifications (34).
5.3.2.2 Pattern Classification
Breast cancer data from the machine learning repository maintained by the Computer
Science Department at the University of California, Irvine (49), will be used to illustrate
how an SOFM can be used to map high-dimensional feature vectors into a 2D space. The
publicly available dataset consists of 683 fine needle aspirate (FNA) tissue samples pro-
vided by Dr. William H. Wolberg (50-52), University of Wisconsin Hospitals, Madison,
and is preclassified into two categories: malignant and benign tissue samples. Every FNA
tissue sample is a vector consisting of nine attributes: clump thickness, uniformity of cell
size and shape, marginal adhesion, single epithelial cell size, bare nuclei, bland chromatin,
and normal nucleoli and mitoses, all of which need to be considered to make a diagnosis.
Each attribute is assigned a value on a scale of 1-10 by the pathologist, 10 indicating a very
high probability of malignancy (50).
Data vectors are randomly selected and presented to the 10
10 SOFM network. An initial
neighborhood of 3 U radius is selected and the network is trained for approximately 1,000
cycles. Upon completion of training the SOFM, a second adaptation algorithm based on
LMSs is used to adjust the weights of layer 2. A learning rate of 0.1 is used and the tolerance
for correct classification was set to 0.0001. The weights of the second layer
w
m
were trained
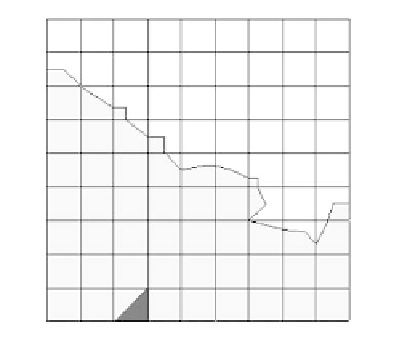
for 10,000 iterations. The separation boundary shown on the resultant map (Figure 5.9) was
based on the output of the classification nodes in layer 2. All test data vectors were correctly
classified except the one false match identified by (X) in the figure.
The success of the unsupervised clustering technique is however dependent upon the
signal signatures or features used for clustering. A poorly selected feature set can result
in numerous incorrect classifications regardless of the effectiveness of the clustering
algorithm employed. This will always be a problem because of the garbage-in garbage-
out principle of information processing. The computational time required to achieve a
usable result is significant and does not lend itself to real-time applications. The problems
arising from selecting appropriate feature sets or incomplete feature sets must still be
Error in
classification
10
X
9
Benign
8
7
6
5
J
Classification
boundary
4
FIGURE 5.9
The decision boundary for the Wisconsin
breast cancer training data as determined
by 10
3
Malignant
2
10 SOFM lattice. The data is sepa-
rated into two classes: malignant and
benign. The 50 test data vectors were cor-
rectly classified except the one shown at
(4,10) as (X).
1
1
2
3
4
5
6
7
8
9 10
I