Graphics Reference
In-Depth Information
We can see the face movements (either synthetic or real) and the content of
the audio tracks jointly influence the decisions of the subjects. Let us take the
first audio track as an example (see Table 5.4). Although the first audio track
only contains neutral information‚ fourteen subjects think the emotional state is
happy if the expression of the synthetic talking face is smile. If the expression
of the synthetic face is sad‚ fifteen subjects classify the emotional state into sad.
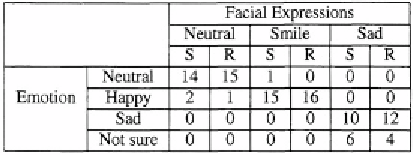
If the audio tracks and the facial represent the same kind of information‚
the human perception on the information is enhanced. For example‚ when the
associated facial expression of the audio track 2 is smile‚ nearly all subjects say
that the emotional state is happy (see Table 5.5). The numbers of the subjects
who agree with happy emotion are higher than those using visual stimuli alone
(see Table 5.2) or audio information alone (see Table 5.3).
However‚ it confuses human subjects if the facial expressions and the audio
tracks represent opposite information. Forexample‚ many subjects are confused
when they listen to an audio track with positive information‚ and observe a
negative facial expression. An example is shown in the seventh and eighth
columns of Table 5.5. The audio track conveys positive information while
the facial expression is sad. Six subjects report that they are confused if the
synthetic talking face with sad expression is shown. The number of the confused
subjects reduces to four if the real face is used. This difference is mainly due to
Search WWH ::

Custom Search