Graphics Reference
In-Depth Information
animation is then rendered synchronously with speech playback. The speech
input and animation playback can run on different PCs via network‚ with only
speech transmitted. To evaluate the effectiveness of our direct mapping method‚
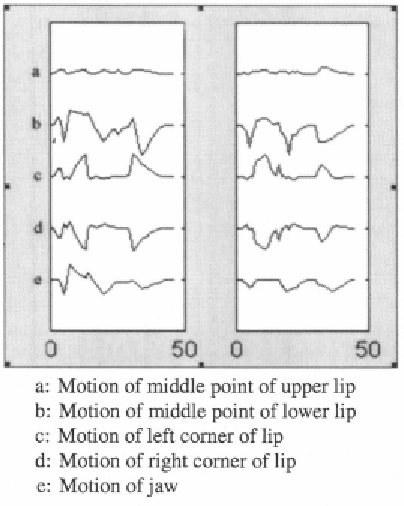
we measure the motions of five points in mouth area synthesized by the direct
mapping method‚ and compare them with the synthetic motion by text driven
method. Figure 5.7 shows an example of the comparison. It can be observed
that the speech driven method produces results comparable to the results of text
driven method‚ which is widely used to generate facial animation.
Figure 5.7.
Comparison of synthetic motions. The left figure is text driven animation and the
right figure is speech driven animation. Horizontal axis is the number of frames; vertical axis is
the intensity of motion.
This system‚ though simple and effective for vowel-like sounds‚ is inadequate
for unvoiced speech‚ and co-articulation is not well taken care of. Nonethe-
less‚ it shows the effectiveness of formant features for real-time speech driven
animation. Next‚ we describe a more comprehensive real-time speech-driven
animation system based on artificial neural network (ANN) in Section 5.2.
5.2 ANN-based real-time speech-driven face animation
In this section‚ we present our real-time speech-driven 3D face animation
algorithm‚ as an animation example based on MUs in our 3D face analysis and
Search WWH ::

Custom Search