Graphics Reference
In-Depth Information
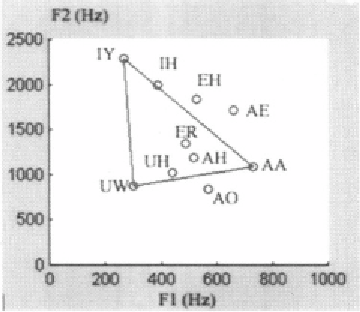
of vowels cluster in a stable triangular subspace (“vowel triangle”). For each
vowel the formants are in a certain region distinguishable form other vowels.
Along a smooth trajectory in the so called “vowel triangle” (Figure 5.6)‚ the
mouth shape changes smoothly. For other vowel-like sounds‚ diphthongs can
Figure 5.6.
“Vowel Triangle” in the system‚ circles correspond to vowels [Rabiner and Shafer‚
1978].
be modeled as transitions between vowels; semivowels are transitions between
vowels and adjacent phonemes. Thus‚ they are (or partly are in the case of
semivowels) trajectories in the "“vowel triangle” [Rabiner and Shafer‚ 1978].
Based on those facts‚ we can define mouth shapes corresponding to vowel-like
sounds as a manifold over the “vowel triangle”. The manifold could be learned
from audio/visual data of recorded human speech. In our approach‚ we choose
to take a much simpler alternative‚ which makes use of the phoneme-viseme
correspondence. Visemes of vowels‚ which are widely used for facial anima-
tion‚ can be seen as observations of the manifold. The mouth shapes in other
places of the manifold can then be approximated by some interpolation tech-
niques. In speaker-independent case‚ the “vowel triangle” is enlarged and there
is overlap between different vowel regions [Rabiner and Shafer‚ 1978]. But
much of a vowel region is still distinguishable from others so that each region
can be roughly related to a unique mouth shape. Thus we can expect that the
mouth shape manifold assumption can still produce reasonable mouth shapes‚
although less natural than the speaker-dependent case. In our system‚ we use
the averaged values of measured formant frequencies of vowels for a wide range
of talkers [Rabiner and Shafer‚ 1978]. For sounds other than vowel-like sounds‚
the proposed mapping is inadequate. Energy envelope modulation is used as a
heuristics‚ to deal with that problem in the system shown in Figure 5.5 .
In the implemented real-time system‚ the average delay between speech input
frame and the generated animation frame is less than 100 ms. The generated
Search WWH ::

Custom Search