Graphics Reference
In-Depth Information
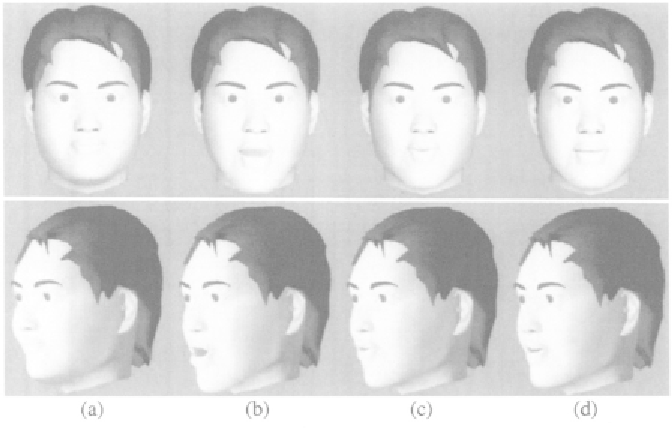
Figure 5.3.
Four of the key shapes. The top row images are front views and the bottom row
images are the side views. The largest components of variances are (a): 0.67; (b): 1.0;, (c):
0.18; (d): 0.19.
using only speech signals requires a complicated continuous speech recognizer,
and the phoneme recognition rate and the timing information may not be ac-
curate enough. The text script associated with speech, however, provides the
accurate word-level transcription so that it greatly simplifies the complexity
and also improves the accuracy. We use a phoneme speech alignment tool,
which comes with Hidden Markov Model Toolkit (HTK) 2.0 [HTK, 2004] for
phoneme recognition and alignment. Speech stream is decoded into phoneme
sequence with timing information. Once we have the phoneme sequence and
the timing information, the remaining part of the procedure of the visual speech
synthesis is similar to text driven face animation.
5. Real-time Speech-driven Face Animation
Real-time speech-driven face animation is demanded for real-time two-way
communications such as teleconferencing. The key issue is to derive the real-
time audio-to-visual mapping. In Section 5.1, we describe a formant-analysis-
based feature for real-time speech animation. Then we present a real-time
audio-to-visual mapping based on artificial neural network (ANN) in Sec-
tion 5.2.
Search WWH ::

Custom Search