Graphics Reference
In-Depth Information
layer neural network to map LPC Cepstrum speech coefficients of one time
step speech signals to mouth-shape parameters for five vowels. Kshirsagar and
Magnenat-Thalmann [Kshirsagar and Magnenat-Thalmann, 2000] also trained
a three-layer neural network to classify speech segments into vowels. Nonethe-
less, these two approaches do not consider phonetic context information. In
addition, they mainly consider the mouth shapes of vowels and neglect the con-
tribution of consonants during speech. Massaro et al. [Massaro and et al., 1999]
trained multilayer perceptrons (MLP) to map LPC cepstral parameters to face
animation parameters. They try to model the coarticulation by considering the
speech context information of five backward and five forward time windows.
Another way to model speech context information is to use time delay neural net-
works (TDNNs) model to perform temporal processing. Lavagetto [Lavagetto,
1995] and Curinga et al. [Curinga et al., 1996] trained TDNN to map LPC cep-
stral coefficients of speech signal to lip animation parameters. TDNN is chosen
because it can model the temporal coarticulation of lips. These artificial neural
networks, however, require a large number of hidden units, which results in
high computational complexity during the training phrase. Vignoli et al. [Vi-
gnoli et al., 1996] used self-organizing maps (SOM) as a classifier to perform
vector quantization functions and fed the classification results to a TDNN. SOM
reduces the dimension of input of TDNN so that it reduces the parameters of
TDNN. However, the recognition results of SOM are discontinuous which may
affect the final output.
2. Facial Motion Trajectory Synthesize
In iFACE system, text-driven and off-line driven speech-driven animation
are synthesized using phoneme sequences, generated by text-to-speech module
or audio alignment tool. Each phoneme
p
corresponds to a key shape, or a
control point the dynamics model in our framework. Each phoneme is modeled
as a multidimensional Gaussian with mean and covariance
A phoneme sequence constrains the temporal trajectory of facial motion at
certain time instances. To generate a smooth trajectory given these constraints,
we use NURBS (Nonuniform Rational B-splines) interpolation. The NURBS
trajectory is defined as:
where is the order of the NURBS, is the basis function, is control
point of the NURBS, and is the weight of Usually people use
or In our framework, we use The phonemes (key facial
configurations) are used as control points, which we assume to have Gaussian
distributions (the method can be trivially generalized to Gaussian mixtures).
The derivation of the phoneme model is discussed in Section 3. We set the
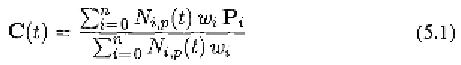
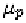

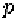

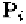
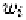
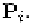
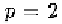
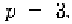

Search WWH ::

Custom Search