Database Reference
In-Depth Information
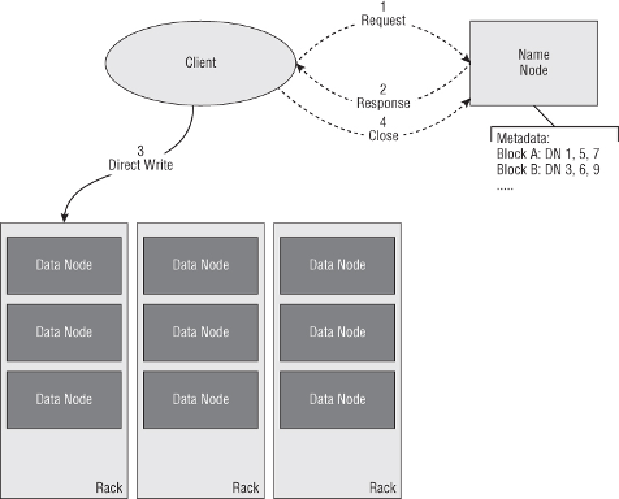
Figure 4.2
HDFS write operation
When a client needs to read a data set from HDFS (see
Figure 4.1
), it
must first contact the NameNode. The NameNode contains all the metadata
associated with the data set or file, including its blocks and all the block
storage locations. The NameNode passes this metadata or information back
to the client. The client then subsequently requests the data directly for each
DataNode.
The pattern of this interaction is important. Although the NameNode acts
as a gatekeeper, after the metadata is provided to the client, it gets out of
the way and allows the client to interact directly with the DataNode. This
provides the foundation for the extremely high level of throughput in HDFS.
Much like the read operation, an HDFS write-operation begins with the
NameNode (see
Figure 4.2
). First, the client requests that the NameNode
create a new empty file with no blocks associated with it. Next, the client
streams data directly to the DataNode using an internal queue to reliably
manage the process of sending and acknowledging the data.