Database Reference
In-Depth Information
Figure 9.19
Mapping output
The output from the map script is fed into the reduce script, which counts
the occurrence of each log level and returns the total count for each log level
on a new line.
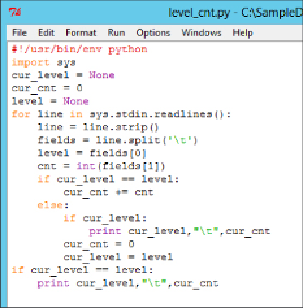
Figure 9.20
shows the code for the reduce script.
Figure 9.20
Reduce script to aggregate log level counts
You combine the map and reduce script into your HiveQL where the output
from the mapper is the input for the reducer. The
cluster by
statement
is used to partition and sort the output of the mapping by the
loglevel
key. The following code processes the log files through the custom map and
reduce scripts:
add file c:\sampledata\map_loglevel.py;
add file c:\sampledata\level_cnt.py;