Database Reference
In-Depth Information
Extending Hive with Map-reduce Scripts
There are times when you need to create a custom data-processing
transformation that is not easy to achieve using HiveQL but fairly easy to
do with a scripting language. This is particularly useful when manipulating
if the result of the transform produces a different number of columns or
rows than the input. For example, you want to split up an input column into
several output columns using string-parsing functions. Another example is
a column containing a set of key/value pairs that need to be split out into
their own rows.
The input values sent to the script will consist of tab-delimited strings,
and the output values should also come back as tab-delimited strings. Any
null values sent to the script will be converted to the literal string
\N
to
differentiate it from an empty string.
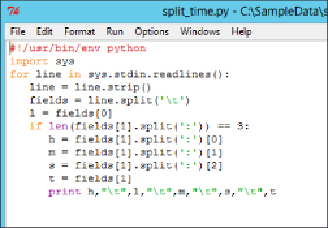
Although technically you can create your script in any scripting language,
Pearl and Python seem to be the most popular. The code shown in
Figure
9.16
is an example Python script that takes in a column formatted as
hh:mm:ss and splits it into separate columns for hour, minute, and second.
Figure 9.16
Python script for splitting time
To call this script from HiveQL, you use the
TRANSFORM
clause. You need
to provide the
TRANSFORM
clause, the input data, output columns, and
map-reduce script file. The following code uses the previous script. It takes
an input of a time column and a log level and parses the time.
Figure 9.17
shows the output:
add file c:\sampledata\split_time.py;
SELECT TRANSFORM(l.t4, l.t2) USING 'python