Database Reference
In-Depth Information
Working with HCatalog and Hive
HCatalog was developed to be used in combination with Hive. HCatalog
data structures are defined using Hive's data definition language (DDL)
and the Hive metastore stores the HCatalog data structures. Using the
command-line interface (CLI), users can create, alter, and drop tables.
Tables are organized into databases or are placed in the default database
if none are defined for the table. Once tables are created, you can explore
the metadata of the tables using commands such as
Show Table
and
Describe Table
. HCatalog commands are the same as Hive's DDL
commands except that HCatalog cannot issue statements that would trigger
a MapReduce job such as
Create Table
or
Select
or
Export Table
.
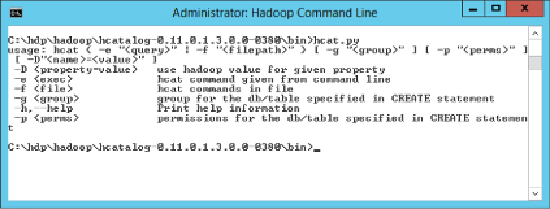
To invoke the HCatalog CLI, launch the Hadoop CLI and navigate to the bin
directory of the HCatalog directory. Enter the command
hcat.py
, which
should result in the output shown in
Figure 7.7
.
To execute a query from the
command line, use the
-e
switch. For example, the following code lists the
databases in the metastore:
hcat.py -e "Show Databases"
At this point, the only database listed is the default database.
Figure 7.7
Invoking the HCatalog CLI.
Defining Data Structures
You can create databases in HCatalog by issuing a
Create Database
statement. The following code creates a database named flight to hold
airline flight statistics tables:
hcat.py -e "Create Database flight"