Biology Reference
In-Depth Information
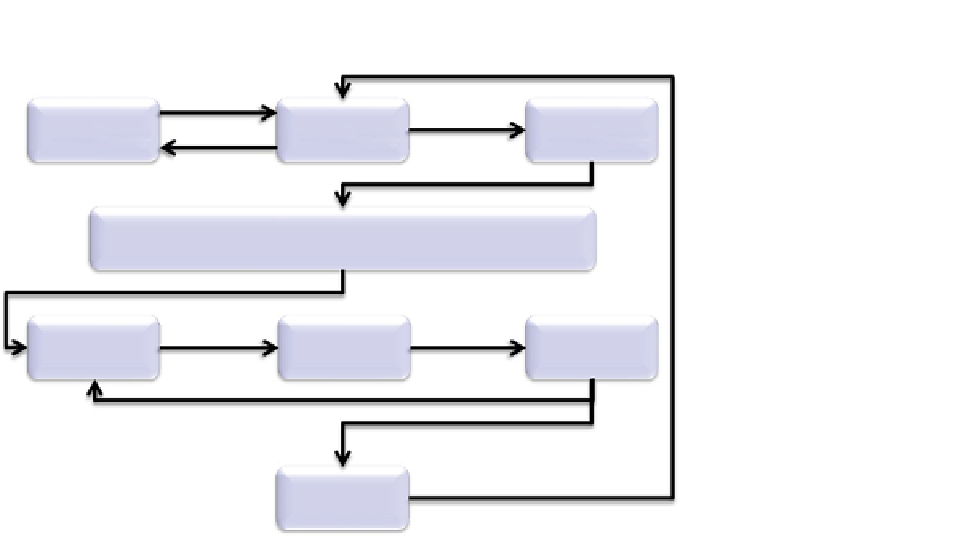
Domain
understanding
Objectives /
hypotheses
Identify
data
Data cleaning, understanding and pre-processing
Select
algorithm(s)
Apply
algorithms
Evaluation
Analysis
FIGURE 2.2
The data mining life cycle.
reported as existing, although they do not occur
in vivo
) and false negatives (inter-
actions which are not recorded in the databases, but which do occur in nature). Most
data mining algorithms attempt to take these issues into account, but the old adage
“garbage in, garbage out” remains true. Data cleaning and pre-processing is perhaps
the most important step of the entire data mining process, and can occupy up to 80%
of the time taken for the project (
Witten
et al.
, 2011
).
Although it is usually impossible to inspect every record individually, summary
statistics can provide a valuable overview of a dataset. The first step with numeric
data is usually to produce a distribution histogram for each variable. Outliers—data
points which are at the extremes of the distribution—can be identified and investi-
gated individually. Some outliers may genuinely be extreme values, which should be
included in later analysis, while others may be due to errors, and can legitimately be
discarded. It is, of course, vital to decide upon a principled set of exclusion criteria.
Other summary statistics such as variable means and ranges, and the production and
inspection of scatterplots can also provide overviews of the data.
Other data manipulations which might need to be performed, depending upon the
data and the analyses to be performed include, but are not limited to:
Scaling
of different types of data with very different ranges
Transformation
so that data has a normal distribution, for some statistical
approaches
Identification of overlap
between different datasets
Identification of statistical correlation
between variables