Information Technology Reference
In-Depth Information
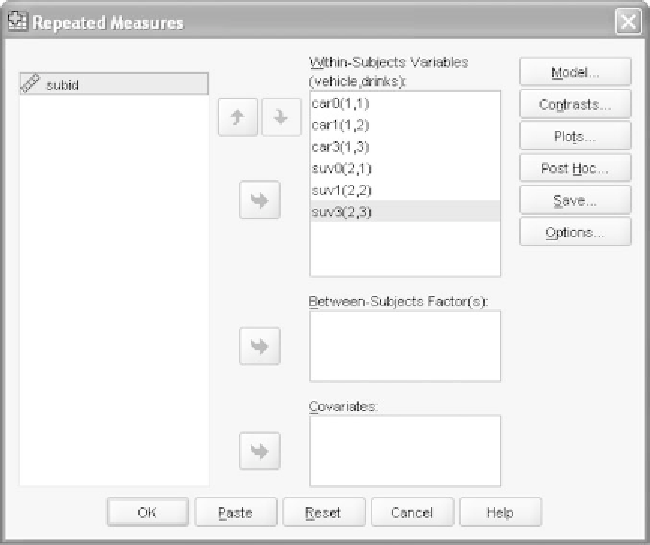
As we view the list of coordinates from top to bottom, the second vari-
able (
drinks
in this case) increments more rapidly than the first variable
(
vehicle
in this case). This is precisely the order of the variables in the
data file, and is not a coincidence. By entering the data in this systematic
manner at the outset, and by naming the variables such that the slowest
incrementing variable in the data file is named first, we have made it very
convenient to define our two independent variables in this window. This
is because the order of the coordinates matches the order in which the
variables appear in the
variables list
in the left panel of the main
GLM
Repeated Measures
window.
Knowing the order in which we need to bring the variables over to the
cell coordinates, we can now bring them over. The first variable brought
over will be matched with the (1,1) coordinate, so you need to be very
careful to use the right panel with the question marks and coordinates
as your guide for the ordering of your variables. In our case the ordering
in the
variable list
matches the order in which SPSS needs to be told of
the order in this window, so we can highlight the list from
car0
to
suv3
and bring it over at the same time; SPSS will preserve the ordering of any
highlighted set of variables clicked over. Figure 11.8 shows the levels of
the variables defined.
Figure 11.8
The main
GLM Repeated Measures
window after we have defined our
variables.