Information Technology Reference
In-Depth Information
the variables in the data file from left to right the information for
drinks
“changes” or increments more rapidly than the information for
vehicle
.It
would have been equally appropriate for us to have chosen the alternative
structure
(car0, suv0, car1, suv1, car3, suv3)
with
vehicle
changing faster
than
drinks
. Note that while it would not be incorrect to have entered these
variables in some other nonsystematic order, we strongly advise against
such chaotic behavior. When we specify our within-subjects variables in
the initial SPSS dialog windows, the systematic structure that we used can
facilitate bringing these variables into the analysis (which must be done
in a very systematic fashion).
11.7.2 STRUCTURING THE DATA ANALYSIS
From the main SPSS menu, select
Analyze
➜
General Linear Model
➜
Repeated Measures
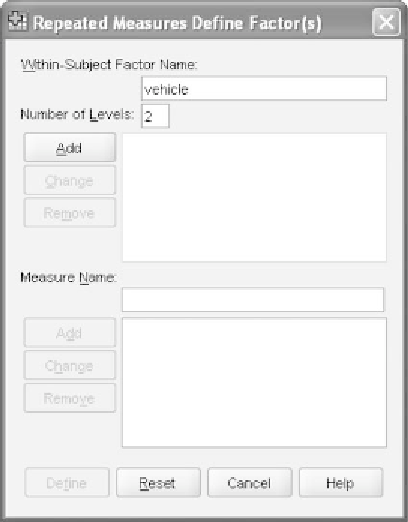
. This will open the dialog window shown in Fig-
ure 11.4. As you will recall from Chapter 10, this is the initial window used
by SPSS to have you name the within-subjects variable(s) in the study and
to indicate the number of levels it has.
Having two within-subjects independent variables calls for defining
each of them separately. Remember how we structured the data file. The
variable named
vehicle
changed or incremented more slowly than the
drinks
variable. Given this data structure, the first variable we should
name is
vehicle
;thenwecanname
drinks
.
Highlight the default name
factor1
and type in
vehicle
.Thentypein
the number of levels for that within-subjects variable, which in this case
is 2. Finally click
Add
.Weseethename
vehicle
appear in the panel to
Figure 11.4
The initial
GLM Repeated Measures
dialog window.