Information Technology Reference
In-Depth Information
Per-VE network bandwidth reservations can be used to ensure that a par-
ticular workload always has the bandwidth it needs, even if that means wast-
ing some bandwidth.
■
Need for Availability
With one workload per system, a hardware failure in
a computer can affect only that workload and, potentially, workloads on other
systems on which it depends. Consolidating multiple unrelated workloads onto
one system requires different planning, because a hardware failure can then
bring down multiple services. High-availability (HA) solutions are justified by the
greater total value of workloads in the computer.
Fortunately, VEs can be configured as nodes in HA clusters using products such
as Oracle Solaris Cluster or Veritas Cluster Server. If you want to minimize just
downtime due to application failure or OS failure, the primary and secondary VEs
can be configured on one computer.
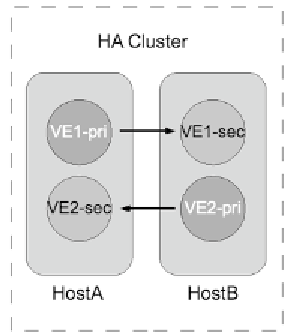
More commonly, the two nodes are configured on different computers to mini-
mize downtime due to hardware failure. Multiple HA pairs can be configured
in the same cluster. Often, primary nodes are spread around the computers in
the cluster to balance the load under normal operating conditions, as shown in
Figure 1.6. This configuration requires sufficient resources on each node to run
both workloads simultaneously if one computer has failed, albeit perhaps with
degraded performance.
Figure 1.6
Load-Balanced Cluster Pairs
A slight twist on the HA concept uses several computers or VEs to simultane-
ously provide the same service to its consumers. With this model, the failure of

Search WWH ::

Custom Search