Database Reference
In-Depth Information
Both anonymous inner classes and lambda expressions can refer‐
ence any
final
variables in the method enclosing them, so you can
pass these variables to Spark just as in Python and Scala.
Common Transformations and Actions
In this chapter, we tour the most common transformations and actions in Spark.
Additional operations are available on RDDs containing certain types of data—for
example, statistical functions on RDDs of numbers, and key/value operations such as
aggregating data by key on RDDs of key/value pairs. We cover converting between
RDD types and these special operations in later sections.
Basic RDDs
We will begin by describing what transformations and actions we can perform on all
RDDs regardless of the data.
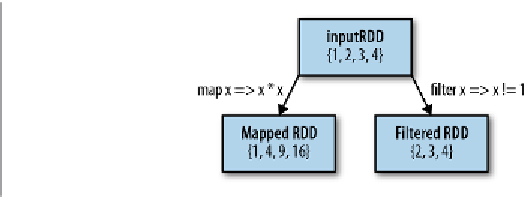
Element-wise transformations
The two most common transformations you will likely be using are
map()
and
fil
ter()
(see
Figure 3-2
). The
map()
transformation takes in a function and applies it to
each element in the RDD with the result of the function being the new value of each
element in the resulting RDD. The
filter()
transformation takes in a function and
returns an RDD that only has elements that pass the
filter()
function.
Figure 3-2. Mapped and filtered RDD from an input RDD
We can use
map()
to do any number of things, from fetching the website associated
with each URL in our collection to just squaring the numbers. It is useful to note that
map()
's return type does not have to be the same as its input type, so if we had an
RDD
String
and our
map()
function were to parse the strings and return a
Double
,
our input RDD type would be
RDD[String]
and the resulting RDD type would be
RDD[Double]
.