Database Reference
In-Depth Information
Example 3-14. union() transformation in Python
errorsRDD
=
inputRDD
.
filter
(
lambda
x
:
"error"
in
x
)
warningsRDD
=
inputRDD
.
filter
(
lambda
x
:
"warning"
in
x
)
badLinesRDD
=
errorsRDD
.
union
(
warningsRDD
)
union()
is a bit different than
filter()
, in that it operates on two RDDs instead of
one. Transformations can actually operate on any number of input RDDs.
A better way to accomplish the same result as in
Example 3-14
would be to simply filter the
inputRDD
once, looking for either
error
or
warning
.
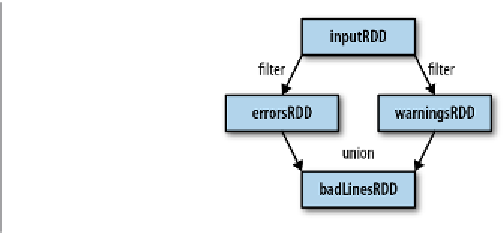
Finally, as you derive new RDDs from each other using transformations, Spark keeps
track of the set of dependencies between different RDDs, called the
lineage graph
. It
uses this information to compute each RDD on demand and to recover lost data if
part of a persistent RDD is lost.
Figure 3-1
shows a lineage graph for
Example 3-14
.
Figure 3-1. RDD lineage graph created during log analysis
Actions
We've seen how to create RDDs from each other with transformations, but at some
point, we'll want to actually
do something
with our dataset. Actions are the second
type of RDD operation. They are the operations that return a final value to the driver
program or write data to an external storage system. Actions force the evaluation of
the transformations required for the RDD they were called on, since they need to
actually produce output.
Continuing the log example from the previous section, we might want to print out
some information about the
badLinesRDD
. To do that, we'll use two actions,
count()
,
which returns the count as a number, and
take()
, which collects a number of ele‐
ments from the RDD, as shown in Examples
3-15
through
3-17
.