Database Reference
In-Depth Information
Decision trees and random forests
Decision trees are a flexible model that can be used for both classification and regres‐
sion. They represent a tree of
nodes
, each of which makes a binary decision based on
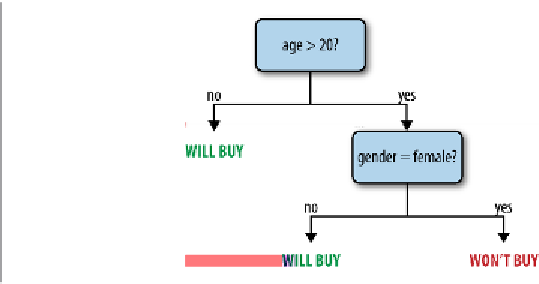
a feature of the data (e.g., is a person's age greater than 20?), and where the leaf nodes
in the tree contain a prediction (e.g., is the person likely to buy a product?). Decision
trees are attractive because the models are easy to inspect and because they support
both categorical and continuous features.
Figure 11-2
shows an example tree.
Figure 11-2. An example decision tree predicting whether a user might buy a product
In MLlib, you can train trees using the
mllib.tree.DecisionTree
class, through the
static methods
trainClassifier()
and
trainRegressor()
. Unlike in some of the
other algorithms, the Java and Scala APIs also use static methods instead of a
Deci
sionTree
object with setters. The training methods take the following parameters:
data
RDD of
LabeledPoint
.
numClasses
(classification only)
Number of classes to use.
impurity
Node impurity measure; can be
gini
or
entropy
for classification, and must be
variance
for regression.
maxDepth
Maximum depth of tree (default:
5
).
maxBins
Number of bins to split data into when building each node (suggested value:
32
).