Database Reference
In-Depth Information
Example 10-8. Running the streaming app and providing data on Linux/Mac
$
spark-submit --class com.oreilly.learningsparkexamples.scala.StreamingLogInput
\
$ASSEMBLY_JAR
local
[
4
]
$
nc localhost
7777
# Lets you type input lines to send to the server
<your input here>
In the rest of this chapter, we'll build on this example to process Apache logfiles. If
you'd like to generate some fake logs, you can run the script
./bin/fakelogs.sh
or
./bin/fakelogs.cmd
in this topic's Git repository to send logs to port 7777.
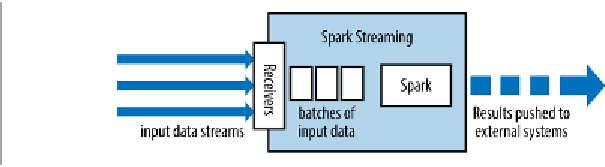
Architecture and Abstraction
Spark Streaming uses a “micro-batch” architecture, where the streaming computa‐
tion is treated as a continuous series of batch computations on small batches of data.
Spark Streaming receives data from various input sources and groups it into small
batches. New batches are created at regular time intervals. At the beginning of each
time interval a new batch is created, and any data that arrives during that interval gets
added to that batch. At the end of the time interval the batch is done growing. The
size of the time intervals is determined by a parameter called the
batch interval
. The
batch interval is typically between 500 milliseconds and several seconds, as config‐
ured by the application developer. Each input batch forms an RDD, and is processed
using Spark jobs to create other RDDs. The processed results can then be pushed out
to external systems in batches. This high-level architecture is shown in
Figure 10-1
.
Figure 10-1. High-level architecture of Spark Streaming
As you've learned, the programming abstraction in Spark Streaming is a discretized
stream or a DStream (shown in
Figure 10-2
), which is a sequence of RDDs, where
each RDD has one time slice of the data in the stream.