Database Reference
In-Depth Information
We now rewrite the query using
CASE
. You'll find that the economized query, shown in
Example 9-15
, is generally faster and much easier to read.
Example 9-15. Using CASE instead of subqueries
SELECT
T
.
tract_id
,
COUNT
(
*
)
As
tot
,
COUNT
(
CASE
WHEN
F
.
fact_type_id
=
131
THEN
1
ELSE
NULL
END
)
AS
type_1
FROM
census
.
lu_tracts
AS
T
LEFT
JOIN
census
.
facts
AS
F
ON
T
.
tract_id
=
F
.
tract_id
GROUP
BY
T
.
tract_id
;
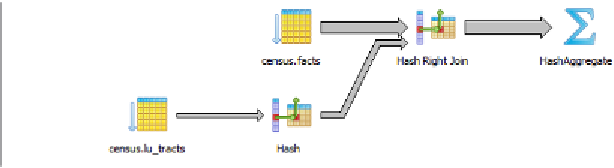
Figure 9-8
shows the graphical plan of
Example 9-15
.
Figure 9-8. Graphical EXPLAIN of using CASE instead
Even though our rewritten query still doesn't use the
fact_type
index, it's faster than
using subqueries because the planner scans the
facts
table only once. A shorter plan
is generally not only easier to comprehend but also often performs better than a longer
one, although not always.
Using Filter Instead of CASE
PostgreSQL 9.4 offers the new
FILTER
construct, which we introduced in
“FILTER
Clause for Aggregates” on page 131
.
FILTER
can often replace
CASE
in aggregate ex‐
pressions. Not only is this syntax pleasanter to look at, but in many cases performs better.
We repeat
Example 9-15
with the equivalent filter version in
Example 9-16
.
Example 9-16. Using CASE instead of subqueries
SELECT
T
.
tract_id
,
COUNT
(
*
)
As
tot
,
COUNT
(
*
)
FILTER
(
WHERE
F
.
fact_type_id
=
131
)
AS
type_1
FROM
census
.
lu_tracts
AS
T
LEFT
JOIN
census
.
facts
AS
F
ON
T
.
tract_id
=
F
.
tract_id
GROUP
BY
T
.
tract_id
;
For this particular example, the
FILTER
performance is only about a millisecond faster
than our
CASE
version, and the plans are more or less the same.