Graphics Reference
In-Depth Information
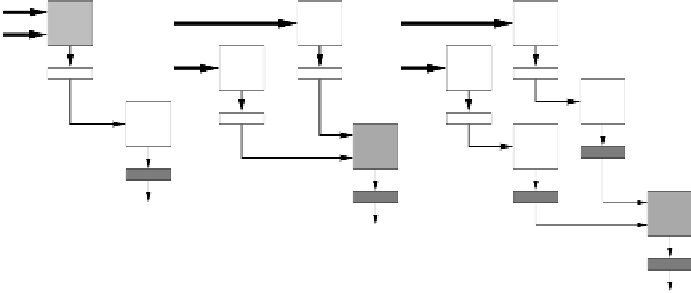
Figure 1.
Schematic depiction of different classifi er architectures: early fusion, mid-level
fusion and late fusion (left to right).
information-gain of the features, and the complexity of the classifier
function. Concatenating features of different sources is advantageous
because the classification task may become separable. However,
extending the dimensionality also implicates to run into the so-called
curse of dimensionality
(Bishop, 2006). Furthermore, in the application
of emotion recognition, early fusion is not intuitive as the individual
sources are likely to have different sampling rates.
Further, it is often necessary to compensate failing sensors that
may occur for example when subjects move away from the camera or
when physiological sensors lose contact to the subject's skin. Hence,
it is intuitive to combine the individual features as late as possible in
an abstract representation.
The mid-level fusion is a good compromise between the two
extremes. Figure 2 shows a layered classifier architecture for recognizing
long-term user categories. According to the key concept, the patterns
are always classified based on the output of the proceeding layer
such that the temporal granularity likewise the level of abstractness
constantly increases. According to the theory, the architecture is able to
recognize classes which are not directly observable (e.g. the affective
state) based on the available evidences (Glodek et al., 2011; Scherer
et al., 2012).
MCSs are widely used in the machine learning community
(Kuncheva, 2004). The performance of an MCS not only depends on
the accuracies of the individual classifiers, but also on the diversity of
the classifiers, which roughly means that classifiers should not agree
on the set of misclassified data. MCSs are highly efficient pattern
recognizers that have been studied by various numerical experiments
and mathematical analysis, and lead to numerous practical applications
Search WWH ::

Custom Search